
User Community Characteristics
Rapidly evolving information technologies are significantly altering social and economic structures both globally and locally. Schools, once dominated by rigid top-down systems, are responding by encouraging more grass-roots opportunities for teachers and producing students who are capable of deriving flexible solutions for a wide-range of problems. One indicator of this restructuring is the movement toward teacher collaboration and empowerment [6, 8].To address the needs for school restructuring and teacher empowerment, systems for distributing educational resources must provide: 1) mechanisms that allow teachers and students to contribute their ideas, 2) a review process to measure the consistency and 3) quality of resources and structures for easily locating valuable resources.
Value is relative. Educational resources that are valuable in one school may be inconsistent with the curricula needs of another school. Moreover, resources are only valuable when they are used; and they are more likely to be used if they have advocates. Educators and students need easy-to-use mechanisms for contributing resources so that they can tailor resources to local needs, and in so doing, become vested in the idea of sharing and using resources. The mechanisms for reviewing the resources should also be distributed so that individuals who are familiar with the local needs can be involved in the review process.
Earlier research and development efforts in designing network information services for educators indicated that teachers initially found hierarchical curricular browsing structures to be an easy way to locate information [1]. As the teachers used the browsing mechanism they became familiar with available resources which included; lesson plans, field trip descriptions, lab activities, videos and professional development and student created materials. With this familiarity of the information domain also came a desire to more precisely focus their queries. They were no longer content with wading through the resources in the "Natural Science" curriculum on "Ecology." Instead, they began to focus their queries more precisely with questions such as, "I need ecology lab activities for grade 4 students that help to develop observation and analytical skills." These kinds of questions require more advanced document indexing and query mechanisms than the parent-child hierarchy needed for a curricular browsing structure.
Database
UNITE uses databases to organize the available resources. Each
database has a configuration file associated with it which describes
the structure, format, and treatment of the database records.
Databases can store several classes of information and must be capable
of managing significantly different kinds of data (i.e., software,
text, video, sound, etc.). The database configuration language is
used to specify record structure, and defines four basic objects:
TABLE, ENUMERATION, RECORD, and DATABASE OBJECT. This language
provides a centralized user-readable and modifiable specification of
the data stored and its treatment by the system. Figure 2
illustrates a simple example of a database configuration file.
TABLE "PhysMedia_Table" {
"CD" "CD_icon.GIF";
"LP" "LP_icon.GIF";
"VHS" "VHS_icon.GIF";
"DEFAULT_ENTRY" "Default_icon.GIF";
}
ENUMERATION "PhysMediaT" {
"CD" "LP" "VHS"
}
ENUMERATION "CurricT" {
"Mathematics"
"Natural Science" {
"General Natural Science"
"Physical Science" {
"General Physical Science"
"Properties of Matter" {
"General Properties of Matter" }
"Electricity-Magnetism" }
"Common Themes"
} }
RECORD "FileDescT" {
"integer" "One" "NoSearch" "FileSize";
"string" "One" "Keyword" "FileName";
}
DATABASE_OBJECT UNITEResource 1994092001 {
"string" "One" "Keyword" "Title";
"uid" "One" "NoSearch" "IDNumber";
"FileDescT" "One" "NoSearch" "FileDesc";
"CurricT" "One" "Keyword" "Curriculum";
"PhysMediaT" "One" "Keyword" "PhysMedia";
}
Figure 2: Data Base Configuration Language Example
The DATABASE OBJECT section defines a UNITE resource's fields and
field attributes, using one line per field. The first attribute is the
field type which can either be a predefined or a user defined type.
The predefined types are: string, integer, and freetext. The user
defined types are either enumerations or records. The next attribute
specifies how many items the field can contain: One, OneOrMore,
ZeroOrMore, or Zero. The third attribute specifies how the field is
used during a search, while the last attribute is the name of the
field used by the database.
In the example of Figure 2, the last line of the database record section specifies that the field "PhysMedia" is of type "PhysMediaT" which is an ENUMERATION representing the set of values "CD", "LP", and "VHS". The "PhysMedia" field may only hold one entry. If "PhysMedia" needed to hold a list of one or more entries then "One" would have been "OneOrMore". The RECORD objects use the same set of parameters as the DATABASE OBJECT, but the record defined is used as a type for a field in the DATABASE OBJECT rather than defining an object directly. In our example the field "FileDesc" is of type "FileDescT" which is a record containing the "FileSize" and "FileName" fields. The ENUMERATIONs defined are also used as type definitions and specify a specific set of field values. In the example, "PhysMediaT" is a simple list, while "CurricT" is a hierarchical list.
The TABLE section gives extra flexibility to the system by defining a mapping from one set of values to another. In the example, the table "PhysMedia_Table" maps the elements of the enumeration "PhysMediaT" to the icons used to represent them in the generated HTML. Another example might be to map each field of a database record to its proper printing format. Both of these tables would be used to help give a consistent look and feel to the HTML documents produced.
Following the definition of a database, the records need to be entered
and ultimately presented to the user. The records are indexed using
the CSO database and are then rendered in HTML. The HTML generation
is currently done at contribution time but could be done on-demand if
it were desirable to trade time for space.
Server
The UNITE server is based on HTTP which allows it to be used as a
regular Web server. It supports the GET, DELETE, POST, PUT, and
SEARCH methods. It runs CGI scripts and supports user directory
access. On the other hand, the UNITE server does not support
directory indexing, authentification, and a number of other services
which were not required for our driving application.
The SEARCH method is a unique feature of the UNITE server. It was created to allow the server to directly respond to queries from the client rather than via CGI scripts. It also defines a search syntax, which has yet to be done by the Web community. To support access from other WWW clients, which do not support the SEARCH method, a generic forms interface to the search capability was built. This interface allows the user to select which database and which fields of the database to search on.
However, the forms interface uses several separate HTML pages to present the search interface, which requires either the client or the server to preserve information across request boundaries, which contradicts the stateless orientation of HTTP. To solve this problem, the server generates HTML documents which preserve the required information in a form invisible to the user. This information is then sent back to the server with each exchange providing the server exactly what it needs to know from previous user interactions. This effectively builds state into the stateless HTTP protocol.
The current search engine used for UNITE is CSO. CSO was originally written for a simple name service, a computer resident phone book, but required only slight modified to fit UNITE's needs. It can keep relatively small amounts of information about a relatively large number of objects, and provide fast access to that information over the Internet [5]. CSO also allows for wild card expansion which permits users to be conveniently vague when formulating queries. The main problem with CSO is that it is inappropriate for large target text items and it does not have Boolean search capabilities. This motivated us to implement set operations (i.e., and, or, contains, ...).
Another search engine that is currently being integrated into the UNITE server is WAIS. WAIS (Wide Area Information Server) is a free text search engine which would support natural language queries and allow the user to perform inexact searches. Another advantage of WAIS is that it returns a ranked list of matches. This allows the user to select resources that have the best match to the query instead of having to browse through a set of resources to find the best.
A necessary part of future work for a truly robust system would be the addition of authentification. A design has been discussed but not implemented. The design calls for a separate database containing user information (i.e. name, username, password, etc ...). Every time a request comes in, the server would query the user database for a proper username/password combination. Users could be a member of a group or groups and each group or user would have specific permissions associated with them. Each database record would also have permissions associated with them, noting which groups or users are allowed to view them. At this point, the server would match users with their groups and then would try to match the user's groups with the database record's groups.
Similar to other more generic Web servers, the UNITE server needed to
handle a large number of requests in a small amount of time. To test
response, an HTML document containing more than 200 in-lined images
was generated and a Web client requested the document. After
approximately 50 GETs for the images, the server ceased responding.
To address this problem, we propose adding a new method to the server
similar to the FTP mget method. For example, a client would
send the MGET method with a list of the documents it wants to
download. The server then serves the client by sending each file with
pre-defined separator between documents. This would reduce the load
on the server since only one request is performed at a time. This
idea is currently being studied as a possible solution to the problem.
Another way to alleviate this problem, which is currently implemented
by the UNITE client, is to cache images on the client side. This
reduces the number of requests since the images are already on the
user's machine.
Client: User Interface
We based the initial design for the client's user interface on a
prototype developed during earlier pilot projects
[1]. This
design used a layered approach to represent a curriculum hierarchy
browsing structures similar to the approach used to represent
directories in typical graphical user interfaces. Novice users
understand how to navigate this structure and they are successful in
locating useful resources. They also appreciate the use of icons to
represent the various resource types. The pilot users also provided
several suggestions for improving the client interface. Key among
these were suggestions for a more efficient browsing view of the
curriculum's hierarchy, and the ability to locate items using multiple
selection criteria.
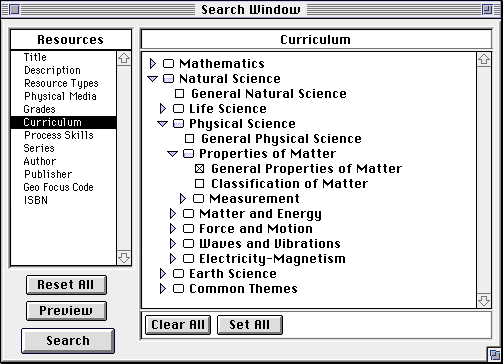
Figure 3: The Explorer Client Search Window
We began the design process for the current user interface in early 1993. In 1993, the most prevalent browsers for distributing resources on the Internet the University of Minnesota's "Gopher" and Dartmouth's "Fetch." However, WWW development was underway at the University of Kansas, most notably the "Lynx" text-based browser, and NCSA was demonstrating an early version of the Mosiac client for the UNIX platform. One of the reasons we decided to pursue WWW development was that HTML offered a more extensible means for designing user interfaces. We knew WWW clients were planned for other platforms but a Macintosh client was not available and the 52 pilot schools in the Great Lakes Collaborative were seeded with Macintosh 610 computers. We decided to develop a Macintosh client that was tailored for the needs of this user community while maintaining server and document compatibility with other WWW development.
The first client delivered in the Fall of 1993 offered a layered folder view as well as an outline view that showed the entire curriculum hierarchy in a single scrolling window. Icons are used to represent resource types in lists and the grade level designation appears at the end of list items. Resources are accessible through a simple point and click interface. We refined the scheme for indexing the documents to be consistent with the emerging standards of the National Science Teachers Association (NSTA) and the National Council of Teachers of Mathematics (NCTM). This indexing allowed us to implement a search window for specifying queries according to several dimensions including; TITLE, GRADE LEVEL, CURRICULUM, PROCESS SKILLS, RESOURCE TYPE and MEDIA TYPE.
Our recent user interface development has centered on incorporating
recent additions to HTML for presenting an easy-to-use interface for
constructing Boolean queries using standard WWW clients. We have also
implemented features in the Explorer client to easily identify
selections in extensive hierarchical lists. The Client Search Window
(Figure 3) shows the user constructing part of a
Boolean query by specifying Curriculum values. Note that the selected
CURRICULUM field is highlighted in the separate window on the left
side of the screen. Having selected the segment of the "Natural
Science Curricula" representing "General Properties of Matter" the
parent portions of the curriculum hierarchy "Properties of Matter,"
Physical Science" and "Natural Science" are shown as partly filled.
Curriculum is one of the controlled vocabularies used in indexing the
educational resources. Other controlled vocabularies shown in this
view include: RESOURCE TYPES, PHYSICAL MEDIA, GRADES and PROCESS
SKILLS. These controlled vocabulary fields may be coupled with the
remaining text entry fields to form complex queries for specifying
resources.
Distributed Aspects
The success of UNITE as a model for distributed access to collections
of information across the Internet depends on a number of factors, but
the single most important is ensuring that the system provides good
support for adding to the database. Our driving application is a
particularly good example of this since the educational materials are
contributed by the users of the system, rather than by some central
authority. However, we believe that this is one of the strengths of
the Internet and represents an important aspect of systems which look
toward the future of the National Information Infrastructure.
First and foremost, the success of such a database requires the participation of users, who are often the best qualified people to generate source material as practitioners in the field. With this in mind, we implemented a method we called the Contribution Process, supported by software called the Contributor. The Contributor must first know to which database the user wishes to contribute a record. Then the Contributor prompts the user to enter information for each field of the database. For example, if the user wanted to contribute a record to the database defined in Figure 2, the Contributor would prompt the user to enter information for the "Title", "FileSize", "FileName", and so on.
The Contributor then sends the newly defined record to a local reviewer. The local reviewer's duties are to make sure the record relates to the application area to which it is being contributed, that it is properly formated, and is well written. The local reviewer then passes the record along to a master reviewer whose duties are to check the local reviewer's work and approve or reject the record for inclusion in the database. From there, the record is sent to the UNITE server for integration in the database. Currently this is done using FTP but in the future the PUT method will be used. The idea here is that the record is sent to a centralized server, keeping the databases consistent by ensuring that there is only one place where new information is introduced to the system.
Once the record is transferred to the server, a series of steps are taken to add the record to the proper section of the database. The first step is to generate an HTML document following the format of the database record definition. Note that this is done on the server and not by the user, keeping a consistent look and feel for all the HTML representations of the database records. Then a database record is created and added to the database. Then it is time to rebuild the layered and outline views and the data structures which will allow the users to request or search for the newly added record. This Contribution Process is run nightly and therefore the turn around time for a newly defined record to be added to the database is usually 24 hours.
To distribute server load and improve availability, UNITE supports a
method of creating multiple copies of a database on multiple server
machines, which is called mirroring. The mirroring process is
run every night and operates in two modes. The first mode makes a
complete copy of the database file structure, including all HTML
documents and all indices built by CSO, to the mirrored server. This
method is usually used for newly added servers or those that have been
inactive for a long period of time. The second method is used for
updates to active mirrors. It determines the set of files modified
since the last update of the mirrored server and sends. None of
mirrored servers are allowed to receive contributions, thus helping to
ensure database consistency.
Conclusions and Future Work
This paper presented the design and development of the UNITE system at the
University of Kansas. The system provides the ability to browse and search
hierarchically indexed resources in a wide range of media types (text, images,
multimedia, etc.). The server provides remote access to Science and
Mathematics resource by geographically distributed K-12 teachers and students,
but it can be easily adapted to work with any hierarchical structured domain.
For example, we have recently constructed a similar database of information
about area businesses for the Lawrence, KS Chamber of Commerce.
The server software supports mirroring, which helps distribute the client load, and enables the client to try alternative servers when its first choice is unavailable. The growth of the database is supported by the contributor software which helps manage the introduction of material produced by users into the database.
The system has been in use by its target audience for over two years and services thousands of requests per week. The experience gained in implementing the system has demonstrated a number of ways in which providing usable services with the WWW presents unique challenges. As such it has demonstrated the need for modifications of current methods, the need for new abilities, and the fact that the WWW is still a vital and evolving entity.
One area of research that is underway concerns the relative benefits of different browsing structures on the user's understanding of the information domain. The browsing structure based on a single indexing dimension (e.g. curriculum) are easy to use put they provide a somewhat constrained understanding of the scope of the resource. We have recently implemented the "EduLette" browser that randomly selects resources from a given domain. We plan to refine this random browser so that user become actively involved in identify the dimensions of the domain they wish to browse. We anticipate that this targeted random browsing coupled with the existing browsing structures will elicit a more robust understanding of the domain and result in the user constructing more meaningful free text queries.
We are continuing to refine the interface and features of the UNITE system based on user recommendations and the goal of developing a useful system for a wide range of users. This includes accessibility from numerous platforms, improvements to the contributing and review functions and the ability to easily locate meaningful resources in the rapidly expanding collections on the Internet.
We are also investigating the application of the UNITE platform to
other possible research areas. We are beginning to apply this
technology to the needs of a small working groups. This will give us
the opportunity to investigate how to use WWW and HTML methods to
provide effective user interfaces for tools supporting group
aactivites. We are also interested in applying this technology to
providing user interfaces for sophisticated information retrieval
approaches to database access, and for providing access to new types
of information including real-time video.
References
[1] R. Aust. Designing Network Information Services for Educators.
Machine-Mediated Learning, 4(2&3), 1994, pp. 251-267.
[2] T. Berners-Lee, R.T. Fielding, H. Frystyk Nielsen, K. Hughes. Hypertext
Transfer Protocol - HTTP/1.0. INTERNET-DRAFT. March 8, 1995.
[3] T. Berners-Lee, D. Connolly. HyperText Markup Language - 2.0. INTERNET
DRAFT. March 29, 1995.
[4] J. December. New Spiders Roam the Web. Computer-Mediated Communication
Magazine, 1 (5), September, 1994.
[5] S. Dorner. The CSO Nameserv: A Description. Technical Report, Computing
Services Office, University of Illinois at Urbana-Champaign. July 1989.
[6] J. Goodlad. Better teachers for our nation's schools. Kappan,
72(3), 1990, pp. 184.
[7] K. Hughes. Entering the World-Wide-Web: A Guide to Cyberspace. Enterprise
Integration Technologies, May 1994.
[8] G. I. Maeroff. A blueprint for empowering teachers. Kappan,
69(7), 1988, pp. 472-476.
[9] World Wide Web: Proposal for a HyperText Project. CERN, 1989.
http://www.w3.org/hypertext/WWW/Proposal.html.