Chapter 2
Background
2.1 Internet
The Internet is the system that has been interconnected to form one
giant network connecting universities, cities, states, countries, and
continents together. The literal meaning of the word Internet is "network
of networks [5].
2.1.1 Brief History
RAND Corporation, America's foremost Cold War think-tank, first started
the idea of the Internet [9]. Their goal was to find a way to
successfully communicate, coast to coast, after any major disaster,
especially after a nuclear war. The first proposal made public was in 1964
[9].
The proposal specified that there would not be a central
authority. This was a major concern due to the fact that if there was a
central authority, then that site would have been the primary target in any
attack from an enemy, making communication impossible. The principles
involved in the conception of the Internet were extremely simple. It would
be designed from the beginning to transcend its own unreliability. All the nodes
in the network would be equal in status to all other nodes, each node with
its own authority to originate, pass, and receive messages. The messages
themselves would be divided into packets, each packet separately
addressed. Each packet would begin at some specified source node, and
end at some other specified destination node. Each packet would wind its
way through the network on an individual basis [9].
As the years went on more groups became interested in the idea. MIT and
UCLA joined with RAND to do more research. The National Physical
Laboratory in Great Britain set up the first test network in 1968. Then the
Advanced Research Project Agency (ARPA) joined in and decided to fund a
larger project in the United States. The network that was built in the US
consisted of four nodes and was given the name ARPANET. In 1971, the
network consisted of 15 nodes. In 1972, the network increased to 37 nodes.
Thanks to ARPANET, users could share one another's computer facilities
via long-distance and they could share information. By the second year of
operation, however, an odd fact became clear. ARPANET's users had
warped the computer-sharing network into a dedicated, high speed,
federally subsidized electronic post office. One of the first really big
mailing list was "SF-LOVERS" for science fiction fans [9].
ARPA used NCP as its original standard for communication, which stood
for "Network Control Protocol". As time went by and technology moved on,
it was soon noticed that NCP was not very sophisticated and therefore a new
protocol suite came about. This protocol suite was known as TCP/IP. TCP,
"Transmission Control Protocol", converts messages into streams of
packets at the source, then reassembles them back into messages at the
destination. IP, "Internet Protocol", handles the addressing, seeing to it
that packets are routed across multiple nodes and even across multiple
networks with multiple standards like NCP, Ethernet, FDDI, and X.25 [9].
In 1984, the National Science Foundation (NSF), got into the act and set a
fast pace for technical advancement through their Office of Advanced
Scientific Computing. Figure 2-1. shows a conceptual view of
the Internet.
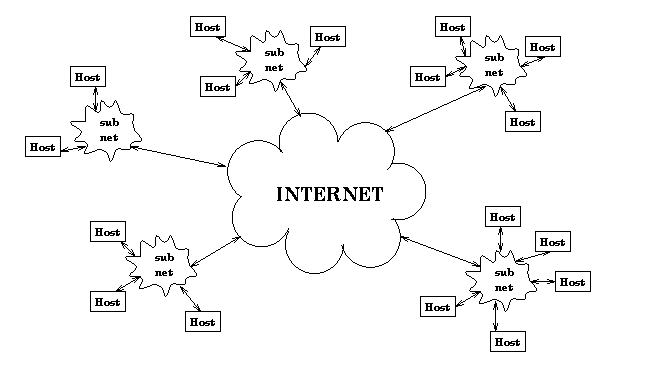
Figure 2-1: Internet
2.1.2 Popularity
On any given day the Internet connects roughly 15 million users in over 50
countries [5].
The use of the Internet is spreading faster than that of cellular
phones and fax machines. In 1992, the Internet was growing at a
rate of twenty percent a month. The number of "host" machines with
direct connection to TCP/IP has been doubling every year since 1988 [5].
Currently, the Internet is growing at a rate of 15% every month.
2.1.3 Uses
The most popular uses of the Internet are: mail, discussion groups,
long-distance computing, and file transfer, in that order [9].
Internet mail is called e-mail, electronic mail. Compared to snailmail, i.e.
the US Postal service, e-mail is faster by several orders of magnitude and it
is also global. E-mail is very similar to the fax machine. The user is
sending electronic text to a receiver. The main advantage over a fax
machine is that e-mail is free.
The discussion groups are generally known as USENET. Any
user with access to USENET can post and read messages. Simply put,
USENET is a crowd of news-hungry people. At the moment, there are some
5,000 separate newsgroups on USENET, and their discussions generate
about 7 million words of typed commentary every single day [9].
ARPANET's original goal of long-distance computing is still widely used.
Programmers have accounts on machines that are more powerful than the
machines they have in their facilities. Therefore, they can write, compile,
and run their programs on better machines from the comfort of their own
office. Also, some libraries will allow users to search their electronic card
catalog. This can greatly reduce the amount of time required to search for
and find a document.
File transfer allows Internet users to access remote machines and retrieve
programs or text. In 1992, there were over a million such public files
available to anyone who requested them [9]. Internet
file-transfer has become a form of publishing in which the reader simply
electronically copies the work on demand, in any quantity he or she wants,
for free. Also, writers use file transfer as a means of proofreading their
works. The author would say that his book is now available on a specific
site. Users will then download it, read it, and give any feedback back to the
author.
2.2 Client/Server
The concept of a client/server application is a process (i.e. the server) on a
remote machine waiting for a request from another process (i.e. the client).
The protocol used is usually
TCP/IP which only provides peer-to-peer communication. This means that
TCP/IP provides a programmer with the ability to establish a communication
channel between two application programs and to pass
data back and forth. On the other hand, TCP/IP does not specify when or
why peer applications interact, nor does it specify how programmers
should organize such application programs in a distributed environment.
2.2.1 The Client/Server Paradigm
Since TCP/IP does not respond to incoming communication requests on its
own, a model had to be designed. This paradigm simply states that "a
program must be waiting to accept communication before any request
arrives [7].
The client/server paradigm, therefore, classifies the communicating
applications into two broad categories, depending on whether the
application waits for communication or initiates it.
2.2.2 The Client
An application that initiates peer-to-peer communication is called the
client. They are usually invoked by the end user when a network service is
used. Most client software consists of conventional application programs.
Each time a client application executes, it contacts a server, sends a
request, and awaits a response. When the response arrives, the client
continues processing [7].
2.2.3 The Server
A server is any program that waits for incoming communication requests
from a client. The server receives a client's request, performs the
necessary computation, and returns the result to the client [7].
2.2.4 Connectionless vs. Connection-Oriented
From the application programmer's point of view, the distinction between
connectionless and connection-oriented interactions is critical because it
determines the level of reliability that the underlying system provides. TCP
provides all the reliability needed to communicate across an internet. It
verifies that data arrives, and automatically retransmits segments that do
not. It also computes a checksum over the data to guarantee that it is not
corrupted during transmission. TCP uses sequence numbers to ensure that
the data arrives in order, and automatically eliminates duplicate packets.
It provides flow control to ensure that the sender does not transmit data
faster than the receiver can consume it. Finally, TCP informs both the
client and server if the underlying network becomes inoperable for any
reason [7].
By contrast, clients and servers that use UDP do not have any guarantees
about reliable delivery. When a client sends a request, the request may be
lost, duplicated, delayed, or delivered out of order. Similarly, a response
the server sends back to a client may be lost, duplicated, delayed, or
delivered out of order. The client and/or server application programs must
take appropriate actions to detect and correct such errors [7].
2.2.5 Stateless vs. Stateful
Information that a server maintains about the status of ongoing
interactions with clients is called state information. Servers that do not
keep any state information are called stateless servers; while others servers
are called stateful servers [7].
The desire for efficiency motivates designers to keep state information in
servers. Keeping a small amount of information in a server can reduce the
size of messages that the client and server exchange, and can allow the
server to respond to requests quickly. Essentially, state information allows
a server to remember what the client requested previously and to compute
an incremental response as each new request arrives. By contrast, the
motivation for statelessness lies in protocol reliability: state information
in a server can become incorrect if messages are lost, duplicated, or
delivered out of order, or if the client computer crashes and reboots. If the
server uses incorrect state information when computing a response, it may
respond incorrectly [7].
2.3 World-Wide-Web
The World-Wide-Web was started at CERN by Tim Berners-Lee in March
1989 as the HyperText Project, and is officially described as a wide-area
hypermedia information retrieval initiative aiming to give universal access
to a large universe of documents [5].
2.3.1 Overview of the World-Wide-Web
Initially, its main goal
was to provide a common (simple) protocol for requesting human readable
information stored on remote systems using hypertext as the interface and
networks as the access method [6]. Hypertext is similar to
regular text since it can be stored, read, searched, or edited, but with an
important exception; hypertext contains connections within the text to other
documents. The generality and power of the World-Wide-Web becomes
apparent when one considers that these links can lead literally anywhere
in cyberspace; to a neighboring file, another file system, or another
computer in another country.
The World-Wide-Web Project adopted a distributed client/server architecture.
The client supports the user as he selects links inside
documents by fetching the new document desired, while the server receives
the requests generated by selecting a link and responds by providing the
client with the required document. At the beginning of the World-Wide-Web
Project, the client was a line mode browser which performed the
display of hypertext document in the client hardware and software
environment. For example, a Macintosh browser uses the Macintosh
interface look-and-feel. In September of 1993, NCSA release the Mosaic
browser for the most common platforms, X-windows, PC/Windows, and
Macintosh. Since Mosaic allowed documents with images to be viewed and
also handled new media formats such as video and sound using helper
applications, it became the World-Wide-Web browser of choice for those
working on computers with graphics capability. However, what may have
been Mosaic's most important property was that it effectively subsumed a
number of traditional services (i.e. ftp, telnet, gopher, ...), and given its
intuitive hypermedia interface, it became the most popular interface to the
World-Wide-Web.
Today the World-Wide-Web is growing at an astonishing rate. From
January to December 1993, the amount of network traffic across the
National Science Foundation's (NSF's) North American network attributed
to World-Wide-Web use multiplied by 187 times. In December 1993 the
World-Wide-Web was ranked 11th of all network services in terms of sheer
traffic - just twelve months earlier, its rank was 127. In June 1993,
Matthew Gray's WWWWanderer, which follows links and estimates the
number of World-Wide-Web sites and documents, found roughly 100 sites
and over two hundred thousand documents. In March 1994 this robot
found 1,200 unique sites. A similar program by Brian Pinkerton at the
University of Washington, called the WebCrawler, found over 3,800 unique
World-Wide-Web sites in mid-May 1994, and found 12,000
World-Wide-Web servers in mid-March of 1995 [5].
The major challenge posed by the World-Wide-Web is clearly one of
organizing and making a wealth of information accessible, not of making it
merely available. The rest of this section gives an overview of important
properties of World-Wide-Web servers and clients, which help determine
what services the World-Wide-Web can provide, and the processing and
network support required to support them.
2.3.2 World-Wide-Web Server
World-Wide-Web servers are programs running on host computers. They
support simultaneous access by multiple users to resources
resident on the server's host. In keeping
with the client/server paradigm, they respond to a specific set of commands
(their protocol) in predictable ways.
Protocol
The World-Wide-Web has used the Hypertext Transfer Protocol (HTTP)
since 1990. HTTP is an application-level protocol with the compactness and
speed necessary for distributed, collaborative, hypermedia information
systems. It is a generic, stateless, object-oriented protocol which can be used
for several kinds of tasks [2]. HTTP builds on the
discipline of reference provided by the Universal Resource Identifier (URI),
such as a location (URL) or name (URN), for identifying the resource upon
which a method should be applied. Messages are passed in a format
similar to that used by Internet mail and use the Multipurpose Internet
Mail Extensions (MIME) [2].
HTTP is based on a request/response between client and server. The client
establishes a connection with a server and submits a request consisting of a
request method, URI, and protocol version, followed by a MIME-like section
containing request modifiers, client information, and optional body. For
most implementations, the connection is established by the client prior to
each request and closed by the server after each response. The closing of
the connection by either or both parties always terminates the current
request, regardless of its status [2].
A client request includes the method which should be applied to the
resource requested, the resource identifier, and the HTTP version. There
are seven different methods allowed in HTTP: GET, HEAD, PUT, POST,
DELETE, LINK, UNLINK [2]. The GET method
retrieves whatever information is identified by the Request-URI. If the
Request-URI refers to a data-producing process, it is the produced data
which is returned as the entity in the response and not the source text of the
process [2]. The HEAD method is identical to GET
except that the server must not return any entity body in the response. The
meta-information contained in the HTTP headers in response to a HEAD
request should be identical to the information sent in response to a GET
request [2].
The POST method is used to request that the destination server accept the
entity enclosed in the request as a new subordinate of the resource
identified by the Request-URI in the request line. POST creates a uniform
method to achieve the following functions: annotation of existing resources;
posting a message to a bulletin board, newsgroup, mailing list, or similar
group articles; providing a block of data (usually a form) to a data handling
process; extending a database through an append operation [2].
The PUT method requests that the enclosed entity be stored under the
supplied Request-URI. If the Request-URI refers to an existing resource,
the enclosed entity is considered a modified version of the original. If the
Request-URI does not point to an existing resource , and the requesting
user agent is permitted to define the URI a new resource, then the server
creates the resource with that URI [2].
The DELETE method requests that the server delete the resource identified
by the Request-URI [2], while the LINK method
establishes one or more link relationships between the resource identified
by the Request-URI and other existing resources. The LINK method does
not allow any entity body to be sent in the request and does not result in the
creation of new resources [2].
The UNLINK method
removes one or more link relationships from the existing resource
identified by the Request-URI. The removal of a link to a resource does not
imply that the resource ceases to exist or becomes inaccessible for future
references [2].
Server Features
The features provided by different servers vary, but currently there are two
popular servers, those produced by NCSA and CERN. The features
discussed in this section are common to both, and are representative of
services which any reasonable HTTP server should provide. One feature,
directory indexing, allows users to view contents of directories on the server
using their World-Wide-Web clients. Depending on how the server was
configured, the listing might specify distinct icons for different file
formats. A header and trailer file could be included in the listing to give
the user more information on the directory contents.
CGI scripts, a particular powerful feature of HTTP servers, are used to run
programs on the server side. These scripts are primarily used as
gateways between the World-Wide-Web programs and other software like
finger, archie, or database software. Image maps, which associate HTTP
links with different areas of an image, are another popular use of CGI
scripts. The images are virtually segmented so when a user clicks on
different parts of the image, he is taken to different URLs. Server features
allow the server administrator to include files within all HTML
documents provided by the server, creating the ability to include a signature
block with every document. When the signature contents change only one
file needs to be changed instead of having to change every file containing
the signature. The server can also restrict access to certain documents or
directories. There are two ways this can be done: (1) in a configuration
file, the server administrator can specify certain hosts that are allowed or
denied access to documents; or (2) the administrator can specify that the
server should ask for a username/password when access to a particular file
or directory is requested.
The features mentioned above are a subset of the features implemented by
full fledged World-Wide-Web servers. Although these features assist the
user in navigating the Internet, the most important feature of a
World-Wide-Web server is its understanding and response to a standard
protocol, providing access to documents from a variety of browsers.
2.3.3 World-Wide-Web Browser
World-Wide-Web clients, often called browsers, mediate between the user
and World-Wide-Web servers by presenting the documents retrieved in a
manner best suited to the user's platform, and makes requests to the
appropriate server when the user selects a hypertext link. Currently, the
most popular browsers are Netscape and Mosaic, both of which are
available for multiple platforms (PC, Mac, UNIX based stations).
HTML
The HyperText Markup Language (HTML) is a simple markup language
used to create hypertext documents that are portable across platforms.
HTML documents are SGML documents with generic semantics appropriate for
representing information from a wide range of applications. HTML can
represent hypertext: news, mail, documentation, and hypermedia; menus of option;
database query results; simple structured documents with in-lined graphics;
and hypertext views of existing bodies of information [3].
HTML has evolved over time, leading clients to render HTML documents
differently. Currently there are three versions of HTML, the most common
being HTML 2.0. HTML 2.0 introduced forms which support more complex
interaction between users and servers by enabling them to supply
information beyond simple item selection. For example, forms are
commonly used by the user to specify character strings for searching, to
provide user-specific data when interacting with a business' World-Wide-Web
page, and to provide written text of many kinds in other situations.
The Netscape browser has extended HTML by adding extra tags and tag
modifiers (i.e. CENTER, BLINK, ...) which provide an enriched set of
document formatting controls to the HTML author. Implementations of
HTML 3.0 recently became available, which adds the features of tables,
mathematical equations, and text wrapping around pictures.
In HTML documents, tags define the start and end of headings,
paragraphs, lists, character highlights and links. Most HTML elements
are identified in a document as a start tag, which gives the element name
and attributes, followed by the content, followed by the end tag. Start tags
are delimited by < and >, and end tags are delimited by </ and >.
Every HTML document starts with a HTML document identifier which
contains two sections, a head and a body. The head contains HTML
elements which describe the documents title, usage and relationship with
other documents. The body contains other HTML elements with the entire
text and graphics of the document. Figure 2-2. gives an example
of an HTML document.
Figure 2-2: HTML example
This example shows the format for a header (<H1> ... </H1>), building a
hypertext link (<A HREF="host.some.where"> link</A>), making a word
bold (<B> ... </B>), and adding an inlined image (<IMG SRC="image.gif">).
Browser Features
The most popular Web browsers, Netscape and Mosaic, provide similar
feature sets. They have a consistent mouse-driven graphical interface and
support the idea of using point-and-click actions to navigate through
documents. They have the ability to display hypertext and hypermedia
documents in a variety of fonts and styles (i.e. bold, italics, ...), layout
elements such as paragraphs, lists, numbered and bulleted lists, and
quoted paragraphs [5]. All of these are defined in the HTML
text of the World-Wide-Web document being rendered.
The browsers have the ability to use external applications to support a wide
range of operations. For example, they can be used to view MPEG or
QuickTime movies, listen to audio files, or display graphical images. With
forms support, they can interact with users via a variety of basic forms
elements, such as fields, check boxes and radio buttons. They provide
hypermedia links to and support for the following network services: FTP,
telnet, gopher, NNTP, and WAIS. In addition, they can: (1) allow remote
applications to control the local display; (2) keep a history of hyperlinks
traversed; and (3) store and retrieve a list of documents viewed for future
use. World-Wide-Web clients often add new abilities along divergent design
paths. However, through HTML, they continue to provide a unified and
uniform interface to the existing information which is the basis of the
WWW's popularity.
2.4 Databases
2.4.1 Database System
A database system is essentially nothing more than a computerized
record-keeping system; that is, it is a computerized system whose overall
purpose is to maintain information and to make that information available on
demand. The information concerned can be anything that is deemed to be
significant to the individual or organization the system is intended to serve
- anything, in other words, that is needed to assist in the general process of
running the business of that individual or organization. Figure 2-3
show a greatly simplified view of a database system. It intends to show that
a database system involves four major components, namely data, hardware,
software, and users [8].
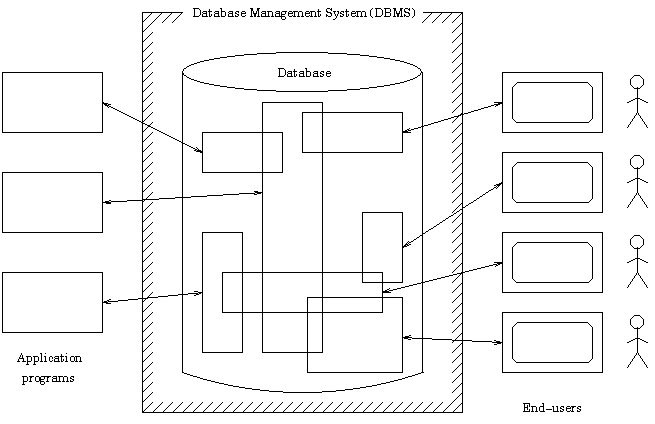
Figure 2-3: Database System Components
2.4.2 Database
The database itself can be regarded as a kind of electronic filing cabinet; in
other words, it is a repository for a collection of computerized data files
[8].
A database consists of some collection of persistent data that
is used by the application systems of some enterprise [8].
Here are a few advantages of a database system over traditional, paper-based
methods of record-keeping: [8].
Currently, the World-Wide-Web is being used to present an exponentially
growing amount and range of information through which people can browse.
This growth of information makes it impossible to locate documents of
interest. A way to solve this problem is to introduce the advantages of
databases to Web servers allowing users to search a document
structure on a server and find the information.