Chapter 3
Framework
3.1 Overview
The framework of the UNITE project consists of an enhanced WWW server,
server tools, and a Macintosh client. These applications provide a
mechanism for users to access multimedia resources in a database. The
contents of the database are contributed by the user community. In our
driving application, a two-stage review process is used to review these
contributions (Figure
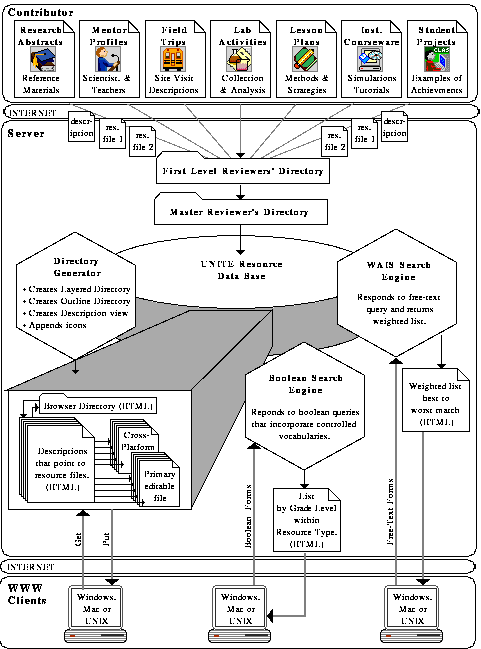
Figure 3-1: UNITE: An Information Service for Contributing, Coordinating and Distributing Educational Resource
3.2 The Database
The database is primarily used to organize the resources. Each database
has a configuration file associated with it which describes the structure,
format, and treatment of the database records. Databases can store several
classes of information and must be capable of managing significantly
different kinds of data (i.e. software, text, video, audio, etc...). A
database configuration language provides a centralized user-readable and
modifiable specification of the data stored and its treatment by the system.
Following the definition of a database, the records need to be entered and
ultimately presented to the user. The records are indexed using the CSO
database and are then rendered in HTML. The HTML generation is
currently done at contribution time but could be done on-the-fly if it were
desirable to trade time for space.
3.3 The UNITE Server
The UNITE server is based on HTTP which has been used by the Web
community since 1990 and therefore allows it to be used
as a regular Web server. It supports the standard request methods with the
addition of the SEARCH method. It runs CGI scripts and supports user
directory access. On the other hand, the UNITE server does not support
directory indexing, authentication, and a number of other services
which were not required for our driving application.
The SEARCH method is a unique feature of the UNITE server. It was
created to allow the server to directly respond to queries from the client
rather than via CGI scripts. It also defines a search syntax, which has yet
to be done by the Web community. To support access from other WWW
clients, which do not support the SEARCH method, a generic forms
interface to the search capability was built. This interface allows the
user to select which database and which fields of the database to search on.
The current search engine used for UNITE is CSO. CSO was originally
written for a simple name service, a computer resident phone book, but
required only slight modifications to fit UNITE's needs. It can keep
relatively small amounts of information about a relatively large number of
objects, and provide fast access to that information over the Internet [4].
CSO also allows for wild card expansion which permits users to be
conveniently vague when formulating queries. Another search engine that
is currently being integrated into the UNITE server is WAIS. WAIS (Wide
Area Information Server) is a free text search engine which would support
natural language queries and allow the user to perform inexact searches.
Another advantage of WAIS is that it returns a ranked list of matches.
This allows the user to select resources that have the best match to the
query instead of having to browse through a set of resources to find the best.
3.4 Client: User Interface
The client was based on a prototype developed during earlier pilot projects [1].
This design used a layered approach to represent hierarchal structures
similar to the approach used to represent directories in typical graphical
user interfaces. Novice users understand how to navigate this structure
and they are successful in locating useful resources. The pilot users also
provided several suggestions for improving the client interface. Key among
these were suggestions for more efficient browsing views of those
hierarchical structures and the ability to locate items using multiple
selection criteria.
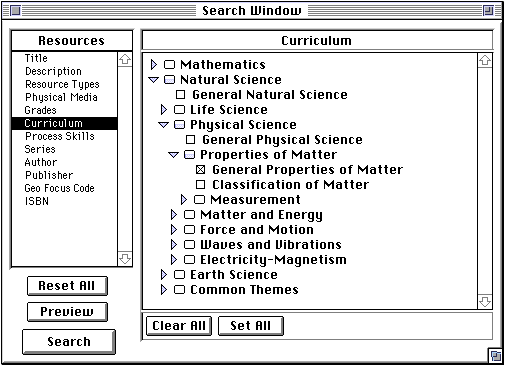
Figure 3-2: The Explorer Client Search Window
The recent user interface development has been centered on incorporating
recent additions to HTML for presenting an easy-to-use interface for
constructing Boolean queries using standard WWW clients. Figure 3-2
shows a user constructing part of a Boolean query by specifying, in this
case, curriculum values. Additional controlled vocabulary fields may be
coupled with remaining text entry fields to form complex queries for
specifying resources.
3.5 Distributed Aspects
The success of UNITE as a model for distributed access to collections of
information across the Internet depends on a number of factors, but the
single most important is ensuring that the system provides good support for
adding to the database. Our driving application is a particularly good
example of this since the educational materials are contributed by the users
of the system, rather than by some central authority. However, we believe
that this is one of the strengths of the Internet and represents an important
aspect of systems which look toward the future of the National Information
Infrastructure.
First and foremost, the success of such a database requires the
participation of users, who are often the best qualified people to generate
source material as practitioners in the field. With this in mind, we
implemented a method we called the Contribution Process, supported by
software called the Contributor. The Contributor must first know to which
database the user wishes to contribute a record. Then the Contributor
prompts the user to enter information for each field of the database. The
Contributor then sends the newly defined record to a local reviewer. The
local reviewer's duties are to make sure the record relates to the application
area to which it is being contributed, that it is properly formatted, and is
well written. The local reviewer then passes the record along to a master
reviewer whose duties are to check the local reviewer's work and approve or
reject the record for inclusion in the database. From there, the record is
sent to the UNITE server for integration in the database. Currently this is
done using FTP but in the future the PUT method will be used. The idea
here is that the record is sent to a centralized server, keeping the databases
consistent by ensuring that there is only one place where new information
is introduced to the system. Once the record is transferred to the server, a
series of steps is taken to add the record to the proper database.
The first step is to generate an HTML document following the
format of the database record definition. Note that this is done on the server
and not by the user, keeping a consistent look and feel for all the HTML
representations of the database records. Once the database record has been
created, it is then added to the database. The final step is to generate a new
layered and outline
view and to rebuild the database indices. This will allow users to request or
search for the newly contributed record.
This Contribution Process is currently run nightly and therefore the
time for a newly defined record to appear in the database is usually 24
hours. To distribute server load and improve availability, UNITE supports
a method of creating multiple copies of a database on multiple server
machines, which is called mirroring. The mirroring process is currently run every
night and operates in two modes. The first mode makes a complete copy of
the database file structure, including all HTML documents and all indices
built by CSO, to the mirrored server. This method is usually used for newly
added servers or those that have been inactive for a long period of time. The
second method is used for updates to active mirrors. It determines the set
of files modified since the last update of the mirrored server and sends.
None of the mirrored servers are allowed to receive contributions, thus helping
to ensure database consistency.