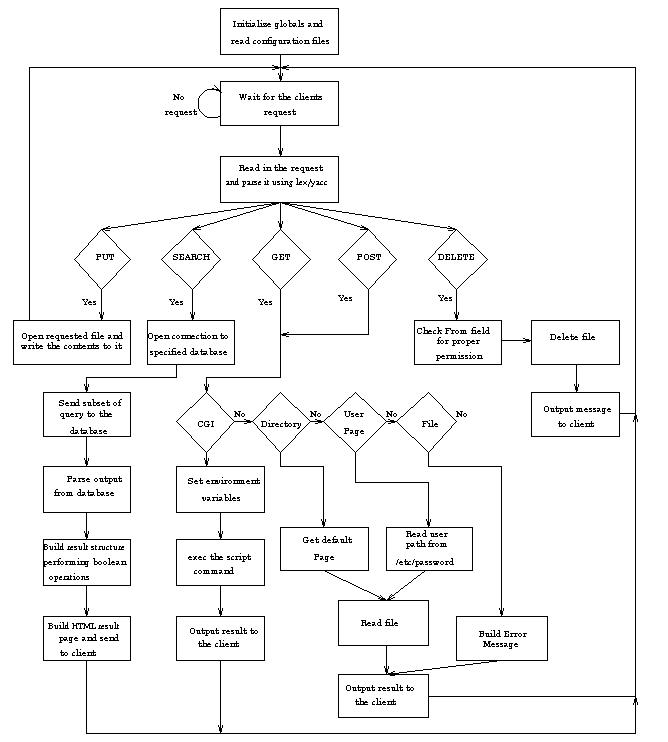
Figure 4-1: UNITE Server Structure
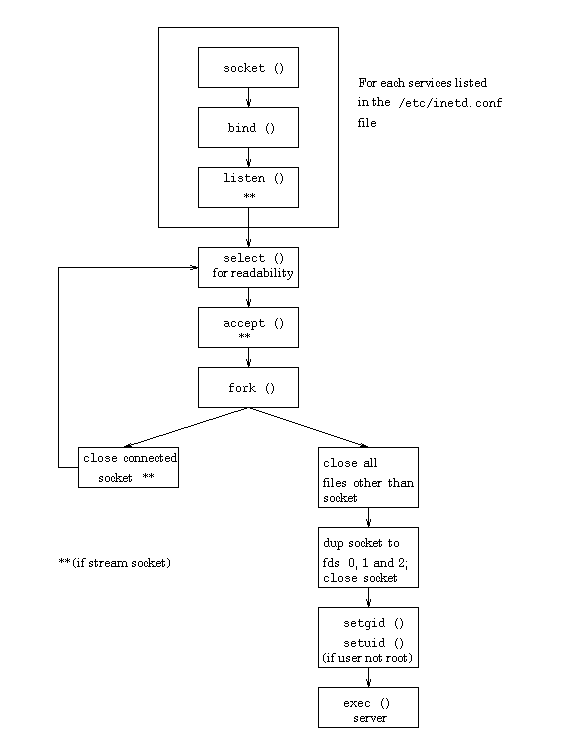
Figure 4-2: Inetd
Figure 4-3: BNF for protocol
The PUT method tells the server that the client wants to add a new file to
the server. The name of the new file is the Request-URI. The server
creates the file containing the Entity-Body sent by the client. All the
parameters concerning the Entity-Body is given in the Entity-Header:
the Content-Length tells the server how many bytes to write to the file and
the Content-Type tells the server the type of the Entity-Body. A message is
then returned to the client informing the user that the operation was
successful. The message displayed to the client is the content of a file,
defined in the global configuration file, on the server and therefore can be
easily modified. Figure 4-4 gives an example for this method.
The protocol-type is the protocol the server understands and is used for
version control. The DBSpec gives the name of one or more databases to
search. If an invalid database name is specified, an error message is
returned informing the client of such an error. If the database specified is
valid, but unavailable, then a different error message is returned. In either
case, an error on a database does not prevent the search process from continuing
on other databases specified in the same query. The SessionSpec gives
resource control parameters. The time-pair specifies the maximum
number of seconds a search may take, the cost-pair specifies the
maximum connection cost that a search may take, and the distance-pair
specifies the maximum distance at which a database may be and still be
searched. If any of these maximums are violated, a message is returned to
the client. A user has the option of overriding the maximum, and continuing
the search, up to a true maximum, or seeing the incomplete search results.
The SearchSpec specifies which records get returned. The operators
defined are and, or, andnot, and contains. The
and, or, andnot perform
the standard Boolean operations, while the contains allows the user to
search for specific values. The ReturnSpec indicates how to present the
identified records, including how to present extremely large retrieval sets.
The max_num_full specifies the number of full record to present,
max_num_sum specifies the number of summary record to present,
max_size_full specifies the maximum size of the full records set in bytes,
max_size_sum specifies the maximum size of the summary records set in
bytes, sort_method is a sort specification with the primary sort key being
the one most nested, show_full_method specifies how to present the
full records, and show_sum_method specifies how to present the
summary records. Figure 4-8 shows an example query sent by the
UNITE client.
The DATABASE OBJECT section defines a UNITE resource'’s fields and field
attributes, using one line per field. This section
is first defined by the keywords DATABASE
OBJECT, followed by a STRING, which is the name of the database.
A NUMBER then follows, which is the version number.
The resource's fields follows, enclosed in braces and delimited
by a semi-colon. The first
attribute of an entry is the field type, which can either be a predefined
or a user defined type. The predefined types are: string, integer, uid, and
freetext. A string is defined as a sequence of characters enclosed in double
quotes, and an integer as a sequence of numbers from 0 to 9.
Freetext is the same as a string except it can contain line feeds. The user
defined types are either enumerations or records. The
next attribute specifies how many items the field can contain: One,
OneOrMore, ZeroOrMore, or Zero. The third attribute specifies how the field
is used during a search, while the last attribute is the name of the field
used by the database.
In the example of Appendix C, the name of the database is
UNITEResource, and the version number is 1994092001. The last entry
of the DATABASE OBJECT
section specifies that the field "Reviewers" is of type "string", can hold
one or more values and is not searchable. As another example, the field
"Curriculum" is of type "CurriculumT" which is an ENUMERATION representing
a set of values that are hierarchically defined. Therefore, the
"Curriculum" field can only contain values that are explicitly defined in
the ENUMERATION "CurriculumT". Some possible values could be: "Mathematics",
"Mathematics/Problem Solving and Reasoning/Generalize" and
"Natural Science/Life Science". "Curriculum" can hold "OneOrMore" values which
means that there has to be at least one value defined and it is a
"KeywordValue" meaning that it is searchable through a keyword based search
engine like CSO.
The other user defined type is a RECORD. This RECORD object uses the
same set of parameters as the DATABASE OBJECT. However, the record defined is used
as a type for a field in the DATABASE OBJECT rather than defining an
object directly. This allows for a more flexible definition of the database.
Following our example in Appendix C, the field "FileDescriptions"
is of type "FileDescriptionsT" which is a RECORD. This RECORD contains a field
"FileDescription" which is of type "FileDescriptionT" which is also a RECORD.
This record contains five fields: "FileSizeInKBytes", "FileFormat",
"FileName", "FileSet", and "FileEncoding".
The TABLE section gives extra flexibility to the system by defining a mapping
from one set of values to another. From the syntax, this section is first
defined by the keyword TABLE followed by a STRING, which is the name of the
table. The table entries then follow enclosed in braces. Each
entry consists of two STRINGs and each entry is delimited by a semicolon.
The first STRING in an entry is used as the index and the second STRING is
mapped to the value.
The ENUMERATION section defines a set of valid values a database field is
allowed to have. The syntax for this section is first defined by the
keyword ENUMERATION followed by a STRING which is the enumeration name. The
content of the enumeration then follows enclosed in braces. All
enumerations are hierarchic. Some hierarchies may just be one level deep
making them look like simple lists. For example, the ENUMERATION
"ResourceTypeT" is a simple list of valid values for the field "ResourceType".
On the other hand, the ENUMERATION "FileFormatT" is a hierarchic list of
valid values for the field "FileFormat". Internally, both of these
enumerations are represented in the same manner.
Following the definition of a database, the records need to be entered and
ultimately presented to the user. The records are indexed using the CSO
database and are rendered in HTML. The HTML generation is currently
done at contribution time but could be done at runtime if it were desirable
to trade time for space.
Figure 4-4: Example for PUT method
Figure 4-5: Example for DELETE method
Figure 4-6: Example for GET method
Figure 4-7: Example for POST method
Figure 4-8: Example for the SEARCH method
4.4 The Databases
The objective of the UNITE project is to allow users to browse and search
resources on a server. Therefore, a database containing resources
had to be configured and a search engine had to be designed.
Each database has a configuration file associated with it which describes
the structure, format, and treatment of the database records. Databases
can store several classes of information and must be capable of managing
significantly different kinds of data (i.e. software, text, video, sound, etc. )
This section will discuss the database configuration file and the search engine
used by the UNITE project.
4.4.1 Database Configuration File
The database configuration language is used to specify record structure, and
defines four basic objects: TABLE, ENUMERATION, RECORD, and DATABASE OBJECT.
This language provides a centralized user-readable and modifiable specification
of the data stored and its treatment by the system. Appendix C
illustrates an example of a database configuration file and Appendix D
gives the syntax of the database configuration file. Appendix E
gives an example of a contributed file built from the database
configuration file.
4.4.2 CSO
The current search engine used for UNITE is CSO. CSO was originally written
for a simple name service, a computer resident phone book, but required only
slight modifications to fit UNITE’s needs. It can keep relatively small
amounts of information about a relatively large number of objects, and provide
fast access to that information over the Internet [4]. CSO also
allows for wild card expansion which permits users to be conveniently vague
when formulating queries. The main problem with CSO is that it is
inappropriate for large target text items and it does not have boolean search
capabilities. This motivated us to implement set operations (i.e. and, or,
contains, ... ).
4.4.3 Adding Databases Engines
To add a new search engine to the UNITE system, only a handfull of functions
would need to be written. First, functions to
format and send the query to the new search engine are needed. Then,
once the search engine returns the results, functions will have to be written
to parse that result in the proper data structures. Finally, the global
configuration file would have to be modified by adding an extra line in the
"databaseLocation" section (refer to the example in Appendix B)
and the database would have to be built.