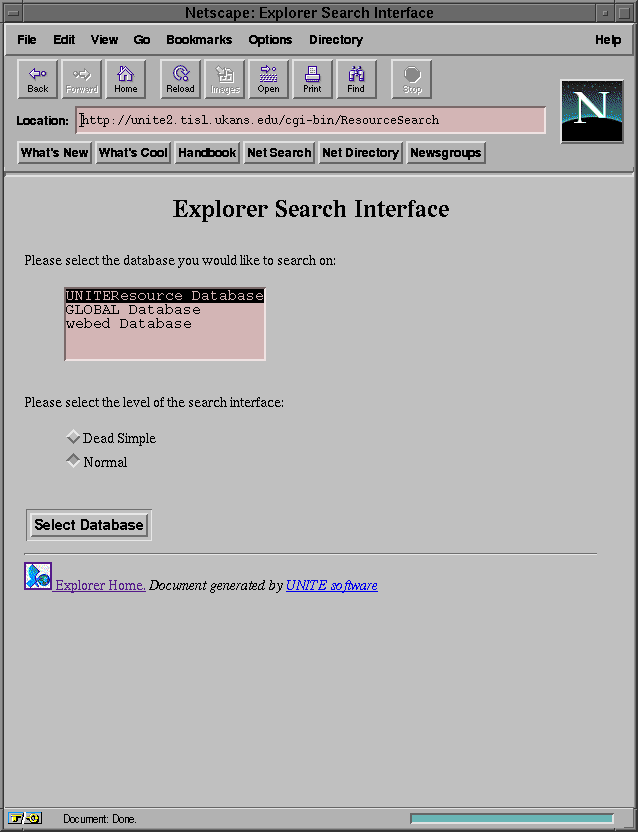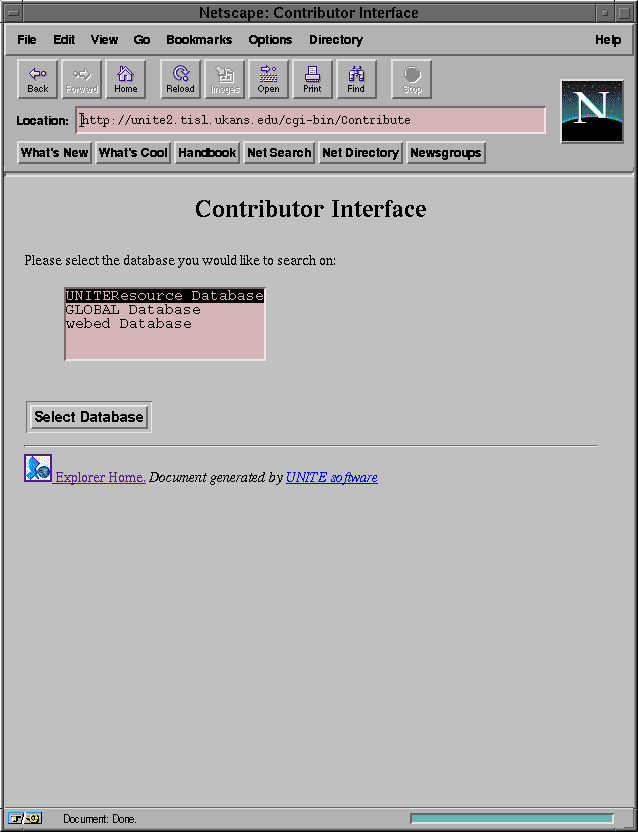
Figure 5-1: Database selection for the contributor through Netscape 1.1N
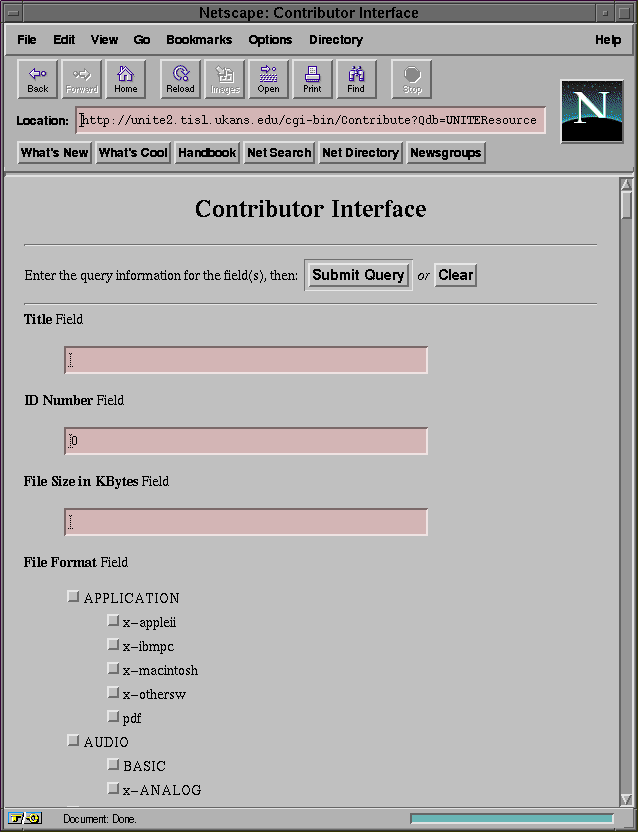
Some resources can be contributed with attached files. These files could be GIFs, MPEGs, or anything the user wants. At this time, this cannot be done through the Contributor on any regular Web browser since file uploads have not yet been incorporated. An Internet draft has been written to address this problem but nothing concrete has been done to solve this problem [11]. The contribution functions are currently done using the UNITE client which was developed concurrently with the UNITE server. To add an attached file to a resource, the "FileDescriptions" field has to be completed. From the database configuration file, this field is of type "FileDescriptionsT", which is a RECORD. This record contains a field called "FileDescription" which is of type "FileDescriptionT" which is also a record. This final record contains five fields: "FileSizeInKBytes", "FileFormat", "FileName", "FileEncoding", "FileSet". These fields must be given a value. Note that if multiple databases are built and attached files are needed for these databases, then these exact fields and records have to be defined with the identical values. Any changes will cause the Renderer to work in properly.
The first administrative duty is to generate a unique identifier (a.k.a. uid). This is done so that duplicate resources will not exist. A field in the database configuration file must be defined as type "uid". If this is not done, errors will occur. The uid is saved in the DBML file as the "IDNumber" field. When the file is originally contributed, the Contributor sets this field to 0 which means that this is a new resource. If the "IDNumber" field is not 0 then the Renderer will use the given uid as the name of the file and remove any previously existing files using the given uid.
Next, the Renderer will add the name of the resource to the "MirrorDir". If the resource is new then a file is created in the "MirrorNewFiles" directory. If the resource is a recontribution then a file is created in the "MirrorUpdatedFiles" directory. The file created is named using the year, month, and day the resource was contributed. This was originally done for mirroring purposes but is now a tool to check what has been contributed and when. The Renderer also adds the name of the resource to the "AuthDir".
Should a contributed resource have an attached file, the Renderer will then read the content of the "FileSet" field and create a file in the "FileSetsDir" containing the name of the resource. The name of the newly created file is the value given in the "FileSet" field.
Following all of this, the Renderer then builds an HTML document from the DBML and moves the file or files (depending on whether or not attached files exist) to its database directory, "ResourceDir". The original file(s) is moved to the "OldContributionDir" as a safeguard.
5.2.1 HTML Builder
To build the HTML file, a library of functions was built. This library can also be used for generating HTML on-the-fly. The HTML is configured using the "htmlPrint.config" file. This file contains methods to build HTML syntax and can, therefore, be changed without having to recompile the program.
All resources are built using the same HTML syntax. Therefore, they
all look alike. The attached files are included as
a link from the main resource to the attached file. Figure 5-3
shows the rendered HTML version of the DBML file included in Appendix E.
The ICON, TEXT, -, and + keywords can all have two additional arguments. The
first argument is a number. This number represents the order in which to sort
the list. In our example, we are first sorting by the ICON field, then by the
- field, and finally by the TEXT field. The number 0 is used to specify not to
sort the field. The second argument is the name of a table. This argument
is used to look up a match in the table for the value of the field. This is
shown in the ICON keyword.
Once the browser is started, HTML formatted files will be created in the
current directory. These files contain the information for displaying the
views. The beginning file for the outline view is tagged with the name "Outline.html" at the end of the file name and
the file for the layered view is tagged with the name "Layer_" at the beginning of the file name. These are the two
files that should be pointed to to initiate the browsing of the database
records.
All of these pages are built from the database configuration file and the
"clientPrint.config" file.
Therefore, any changes to the database will not require any recompilation.
Also, some information had to be passed from page to page. For example,
the name of the database had to be passed from the first introduction page
to the last page. Since the server is stateless, there was no way of doing
this through it. The only way the information could be transferred is through
the forms in the HTML pages. Therefore, the information is passed as a
hidden form. This hidden form is just like a regular text entry form except
it is not visible to the user. The content of the form is passed the same
way as any other form therefore causing a state. The hidden forms are an
added feature of Netscape and have not yet been implemented by Mosaic.
Another necessity was the need to save a query. This cannot be done on the
server since it is stateless and does not know which user is sending a query.
Therefore, this has to be done on the client side. This was easily accomplished using
the GET method for CGI scripts instead of the POST method. The difference
between the two is that the GET method appends all the forms information to
the URL and the POST method does not. Therefore, once a query has been sent
and the user wants to save his query for future use, all he needs to do is
save the page in his bookmark or hotlist. Then when the user later looks
through his bookmarks he can resend a query by simply selecting the URL. This
will send the query back to the server and the updated result will be
returned.
The mirroring script takes three optional arguments and one required
argument. The first optional argument is the host of the mirrored
server, the second is the directory to mirror, and the final is the archive
file.
The required argument is the method used.
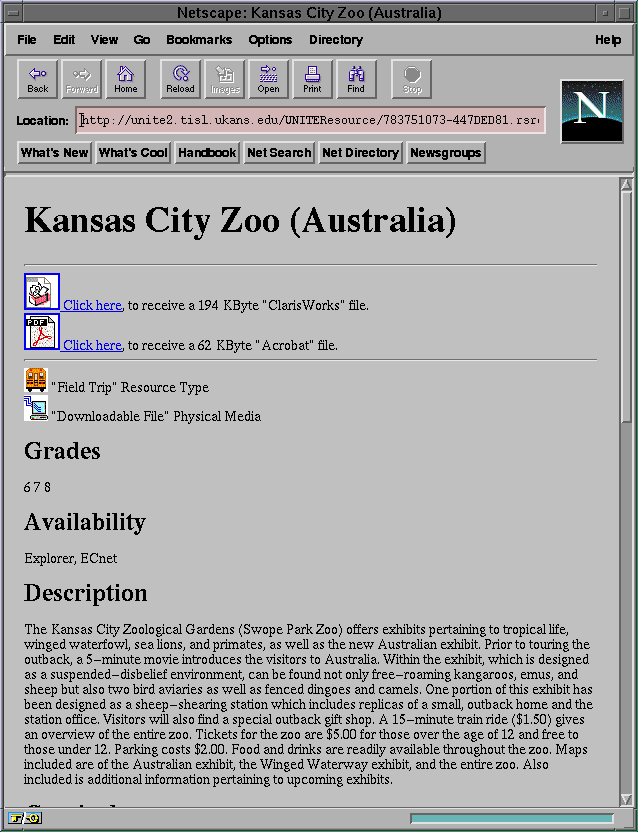
Figure 5-3: HTML rendering of the DBML example
5.3 Browser
The UNITE browser provides views of the database to the user in an
HTML format. The two views are the outline and layered views. These views
are built using a field in the database. In our application, these views are
built using the "Curriculum" field. This field is used because it is a
hierarchic enumeration and all resources have to contain a value since it is
defined to be a "OneOrMore" field (refer to Appendix C). It is
recommended that a hierarchic field be used for the browser since it generates
a layered and outline view. If the field is a flat enumeration, there would
be no difference between those two views. Figures 5-4 and 5-5
show an example of the two views for our application.
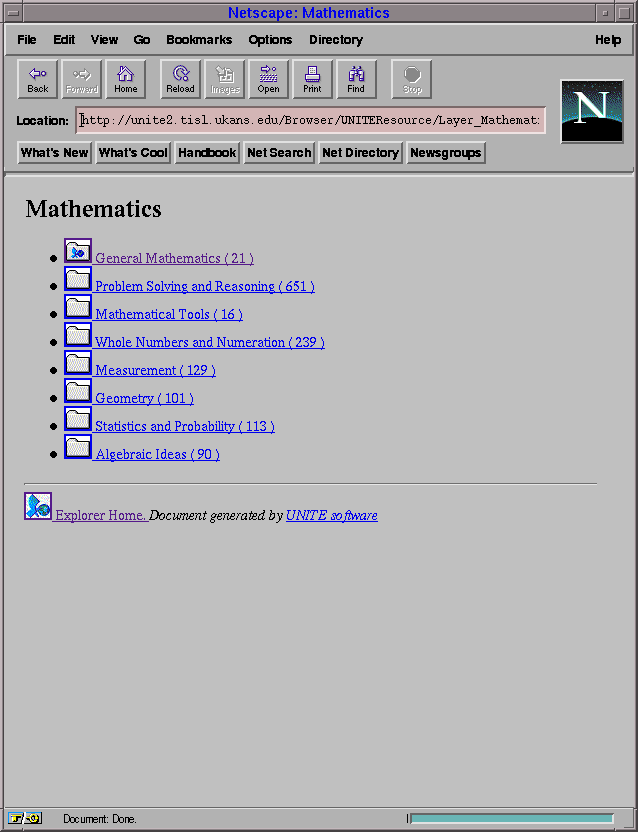
Figure 5-4: Layered view of the database
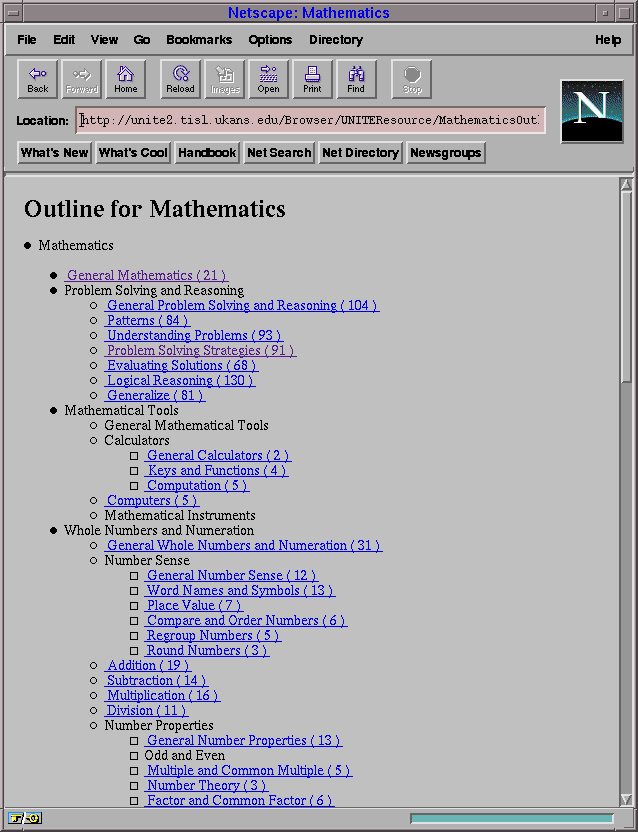
Figure 5-5: Outline view of the database
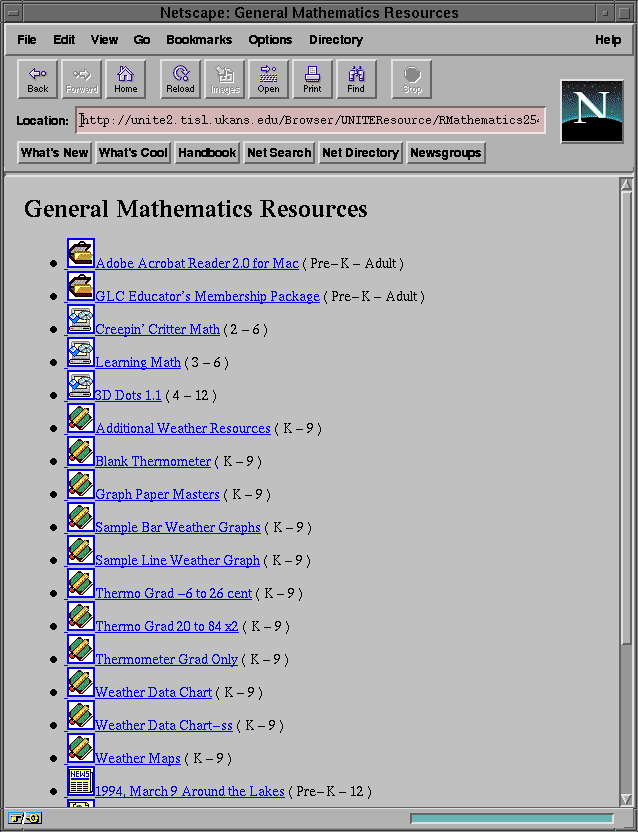
Figure 5-6: List of resources shown while browsing the database
(ANCHOR IDNumber)
(ICON 1 ResourceType ResourceType_Table)
(TEXT 3 Title)
(ANCHOR CLOSE)
" ( "
(- 2 Grades)
" - "
(+ 0 Grades)
" )"
Figure 5-7: Browser configuration file
5.4 Database Builder
One of the tasks necessary when contributing resources is to build the search
engine's index files. Currently, the search engine being used is CSO. This
engine requires two files to be built before it runs its own indexer. The
first file is the configuration file. This file contains a description for
each field. Figure 5-8 shows an example configuration file using
the example database configuration file and shows why a human would not
want to build this file himself.
55:Title:256:Title:O:Indexed:Lookup:Public:Default:
56:IDNumber:256:ID Number:O:Indexed:Lookup:Public:Default:
57:FileSizeInKBytes:256:File Size in KBytes:O:Indexed:Lookup:Public:Default:
58:FileFormat:256:File Format:O:Indexed:Lookup:Public:Default:
59:FileName:256:File Name:O:Indexed:Lookup:Public:Default:
60:FileEncoding:256:File Encoding:O:Indexed:Lookup:Public:Default:
61:FileSet:256:File Set:O:Indexed:Lookup:Public:Default:
62:ResourceType:256:Resource Type:O:Indexed:Lookup:Public:Default:
63:PhysicalMedia:256:Physical Media:O:Indexed:Lookup:Public:Default:
64:Grades:256:Grades:O:Indexed:Lookup:Public:Default:
65:Series:256:Series:O:Indexed:Lookup:Public:Default:
66:Availability:5000:Availability:O:Indexed:Lookup:Public:Default:
67:Description:5000:Description:O:Indexed:Lookup:Public:Default:
68:Curriculum:256:Curriculum:O:Indexed:Lookup:Public:Default:
69:ProcessSkills:256:Process Skills:O:Indexed:Lookup:Public:Default:
70:Author:256:Author:O:Indexed:Lookup:Public:Default:
71:Publisher:256:Publisher:O:Indexed:Lookup:Public:Default:
72:Reviewers:256:Reviewers:O:Indexed:Lookup:Public:Default:
Figure 5-8: Configuration for the CSO search engine
5.5 Search Interface
A search interface was built to allow users to search the content of the
database using a Web browser capable of supporting forms. This search interface
is a simple C program that runs as a CGI script through the UNITE server. The
program first asks the user which database he would like to search on.
The list of the databases is in the "DatabaseList" file defined in the global
configuration file (Appendix B). The user is also asked to
select the level of the interface. Once these selections are done, the user
is asked to choose which fields he would like to search on. If the user
selects the "Dead Simple" level for the interface, then the program will restrict
the user to only one entry per field. If the user selects the normal
level, then the user is asked to select between 1 and 5 entries per fields.
However, not every field can have more than one entry. For example, an
enumeration does not need to have more then one entry since all the choices
are there to select from. Figures 5-9 and 5-10 give
an example of each interface. Figure 5-11 shows the initial
page.
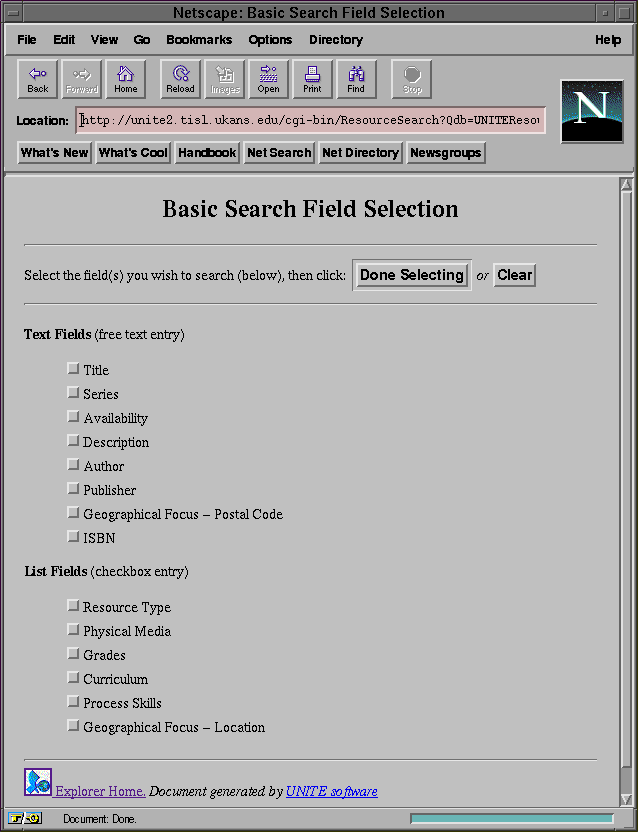
Figure 5-9: The easy search interface
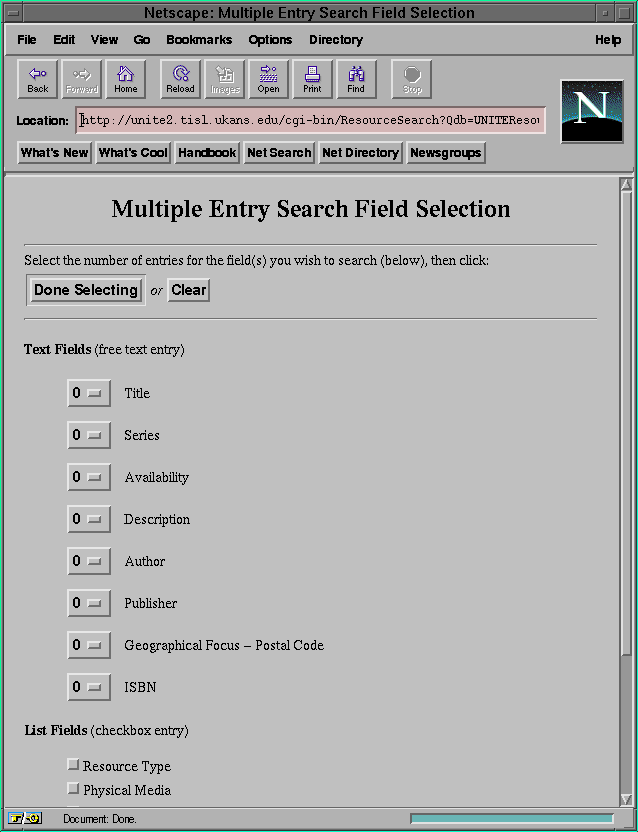
Figure 5-10: The normal search interface
5.6 Mirroring
To distribute server load and improve availability, UNITE supports a
method of creating multiple copies of a database on multiple server
machines, which is called mirroring. The mirroring process
operates in two modes. The first mode makes a
complete copy of the database file structure, including all HTML
documents and all indices built by CSO, to the mirrored server. This
method is usually used for newly added servers or those that have been
inactive for a long period of time. The second method is used for
updates to active mirrors. It determines the set of files modified
since the last update of the mirrored server and sends.
In order to ensure database consistency, none of
mirrored servers should be allowed to receive contributions.
5.7 CGI Scripts
Included with the UNITE system are a few additional CGI scripts. These
scripts are meant as enhancements to the system and are not requirements
for the system to work efficiently.
5.7.1 EduLette
EduLette is a C program that allow users to browse through a database
randomly. The CGI script takes two arguments. The first is the name
of the database and the second is a yes or no. If a database
has a field
named "URL" and the second argument is yes then the program will
automatically take the user to the location specified in the "URL" field.
If the second argument is a no or the field URL does not exist then the
HTML of the resource is returned to the browser.
5.7.2 Home
The Home script is used to segregate Web browsers. This way separate actions
can be taken for each browser. The UNITE team uses it to segregate the
UNITE browser from other Web browsers. This is done because we
did not want links to appear in the UNITE browser. For example, the links
to the search interface are not displayed because the UNITE browser has
its own search interface built-in. To segregate the browsers the script
uses the user_agent field returned by each Web browser.
5.7.3 Imagemap
The Imagemap script was originally written by Kevin Hughes
(kevinh@pulua.hcc.hawaii.edu). Its purpose
is to virtually segment images so that users can click on the different
segments and follow a separate link for each segments. The program was
slightly modified to use the environment variable "QUERY_STRING" instead
of passing the information as arguments to the program.