We examine a version of the dynamic dictionary problem in which stored items have expiration times and can be removed from the dictionary once they have expired. We show that under several reasonable assumptions about the distribution of the items, hashing with lazy deletion uses little more space than methods that use eager deletion. The simple algorithm suggested by this observation was used in a program for analyzing integrated circuit artwork.
We answer questions about the distribution of the maximum
size of queues and data structures as a function of time.
The concept of "maximum" occurs in many issues of resource
allocation. We consider several models of growth, including
general birth-and-death processes, the M/G/![]() model, and a
non-Markovian process (data structure) for processing
plane-sweep information in computational geometry, called
"hashing with lazy deletion" (HwLD). It has been shown that
HwLD is optimal in terms of expected time and dynamic space;
our results show that it is also optimal in terms of
expected preallocated space, up to a constant factor.
model, and a
non-Markovian process (data structure) for processing
plane-sweep information in computational geometry, called
"hashing with lazy deletion" (HwLD). It has been shown that
HwLD is optimal in terms of expected time and dynamic space;
our results show that it is also optimal in terms of
expected preallocated space, up to a constant factor.
We take two independent and complementary approaches: first, in
Section 2, we use a variety of algebraic and analytical
techniques to derive exact formulas for the distribution of
the maximum queue size in stationary birth-and-death
processes and in a nonstationary model related to file
histories. The formulas allow numerical evaluation and some
asymptotics. In our second approach, in Section 3, we
consider the M/G/![]() model (which includes M/M/
model (which includes M/M/![]() as a
special case) and use techniques from the analysis of
algorithms to get optimal big-oh bounds on the expected
maximum queue size and on the expected maximum amount of
storage used by HwLD in excess of the optimal amount. The
techniques appear extendible to other models, such as M/M/1.
as a
special case) and use techniques from the analysis of
algorithms to get optimal big-oh bounds on the expected
maximum queue size and on the expected maximum amount of
storage used by HwLD in excess of the optimal amount. The
techniques appear extendible to other models, such as M/M/1.
This paper develops two probabilistic methods that allow the analysis of the maximum data structure size encountered during a sequence of insertions and deletions in data structures such as priority queues, dictionaries, linear lists, and symbol tables, and in sweepline structures for geometry and Very-Large- Scale-Integration (VLSI) applications. The notion of the "maximum" is basic to issues of resource preallocation. The methods here are applied to combinatorial models of file histories and probabilistic models, as well as to a non-Markovian process (algorithm) for processing sweepline information in an efficient way, called "hashing with lazy deletion" (HwLD). Expressions are derived for the expected maximum data structure size that are asymptotically exact, that is, correct up to lower-order terms; in several cases of interest the expected value of the maximum size is asymptotically equal to the maximum expected size. This solves several open problems, including longstanding questions in queueing theory. Both of these approaches are robust and rely upon novel applications of techniques from the analysis of algorithms. At a high level, the first method isolates the primary contribution to the maximum and bounds the lesser effects. In the second technique the continuous-time probabilistic model is related to its discrete analog-the maximum slot occupancy in hashing.
Parallel algorithms for several graph and geometric problems are
presented, including transitive closure and topological sorting in
planar ![]() -graphs, preprocessing planar subdivisions for point location
queries, and construction of visibility representations and drawings of
planar graphs. Most of these algorithms achieve optimal
-graphs, preprocessing planar subdivisions for point location
queries, and construction of visibility representations and drawings of
planar graphs. Most of these algorithms achieve optimal ![]() running time using
running time using ![]() processors in the EREW PRAM model,
processors in the EREW PRAM model, ![]() being the number of vertices.
being the number of vertices.
Fractional cascading is a technique designed to allow efficient
sequential search in a graph with catalogs of total size ![]() . The
search consists of locating a key in the catalogs along a path. In this
paper we show how to preprocess a variety of fractional cascaded data
structures whose underlying graph is a tree so that searching can be
done efficiently in parallel. The preprocessing takes
. The
search consists of locating a key in the catalogs along a path. In this
paper we show how to preprocess a variety of fractional cascaded data
structures whose underlying graph is a tree so that searching can be
done efficiently in parallel. The preprocessing takes ![]() time
with
time
with ![]() processors on an EREW PRAM. For a balanced binary tree
cooperative search along root-to-leaf paths can be done in
processors on an EREW PRAM. For a balanced binary tree
cooperative search along root-to-leaf paths can be done in
![]() time using
time using ![]() processors on a CREW PRAM. Both of these
time/processor constraints are optimal. The searching in the fractional
cascaded data structure can be either explicit, in which the search path
is specified before the search starts, or implicit, in which the
branching is determined at each node. We apply this technique to a
variety of geometric problems, including point location, range search,
and segment intersection search.
processors on a CREW PRAM. Both of these
time/processor constraints are optimal. The searching in the fractional
cascaded data structure can be either explicit, in which the search path
is specified before the search starts, or implicit, in which the
branching is determined at each node. We apply this technique to a
variety of geometric problems, including point location, range search,
and segment intersection search.
In this paper we present approximation algorithms for median problems
in metric spaces and fixed-dimensional Euclidean space. Our
algorithms use a new method for transforming an optimal solution of
the linear program relaxation of the ![]() -median problem into a
provably good integral solution. This transformation technique is
fundamentally different from the methods of randomized and
deterministic rounding by Raghavan and the methods proposed the
authors' earlier work in the following way: Previous techniques never
set variables with zero values in the fractional solution to the value
of 1. This departure from previous methods is crucial for the success
of our algorithms.
-median problem into a
provably good integral solution. This transformation technique is
fundamentally different from the methods of randomized and
deterministic rounding by Raghavan and the methods proposed the
authors' earlier work in the following way: Previous techniques never
set variables with zero values in the fractional solution to the value
of 1. This departure from previous methods is crucial for the success
of our algorithms.
In this paper we give a practical and efficient output-sensitive
algorithm for constructing the display of a polyhedral terrain. It runs
in
![]() time and uses
time and uses
![]() space, where
space, where ![]() is the size of the final display, and
is the size of the final display, and ![]() is a (very slowly
growing) functional inverse of Ackermann's function. Our implementation
is especially simple and practical, because we try to take full
advantage of the specific geometrical properties of the terrain. The
asymptotic speed of our algorithm has been improved upon theoretically
by other authors, but at the cost of higher space usage and/or high
overhead and complicated code. Our main data structure maintains an
implicit representation of the convex hull of a set of points that can
be dynamically updated in
is a (very slowly
growing) functional inverse of Ackermann's function. Our implementation
is especially simple and practical, because we try to take full
advantage of the specific geometrical properties of the terrain. The
asymptotic speed of our algorithm has been improved upon theoretically
by other authors, but at the cost of higher space usage and/or high
overhead and complicated code. Our main data structure maintains an
implicit representation of the convex hull of a set of points that can
be dynamically updated in ![]() time. It is especially simple
and fast in our application since there are no rebalancing operations
required in the tree.
time. It is especially simple
and fast in our application since there are no rebalancing operations
required in the tree.
Keywords: display, hidden-line elimination, polyhedral terrain, output-sensitive, convex hull.
In this paper, we give new techniques for designing efficient algorithms for computational geometry problems that are too large to be solved in internal memory, and we use these techniques to develop optimal and practical algorithms for a number of important large-scale problems in computational geometry. Our algorithms are optimal for a wide range of two-level and hierarchical multilevel memory models, including parallel models. The algorithms are optimal in terms of both I/O cost and internal computation.
Our results are built on four fundamental techniques: distribution
sweeping, a generic method for externalizing plane-sweep
algorithms; persistent B-trees, for which we have both on-line
and off-line methods; batch filtering, a general method for
performing ![]() simultaneous external-memory searches in any data
structure that can be modeled as a planar layered dag; and
external marriage-before-conquest, an external-memory analog of the
well-known technique of Kirkpatrick and Seidel. Using these techniques
we are able to solve a very large number of problems in computational
geometry, including batched range queries, 2-d and 3-d convex hull
construction, planar point location, range queries, finding all nearest
neighbors for a set of planar points, rectangle intersection/union
reporting, computing the visibility of segments from a point, performing
ray-shooting queries in constructive solid geometry (CSG) models, as
well as several geometric dominance problems.
simultaneous external-memory searches in any data
structure that can be modeled as a planar layered dag; and
external marriage-before-conquest, an external-memory analog of the
well-known technique of Kirkpatrick and Seidel. Using these techniques
we are able to solve a very large number of problems in computational
geometry, including batched range queries, 2-d and 3-d convex hull
construction, planar point location, range queries, finding all nearest
neighbors for a set of planar points, rectangle intersection/union
reporting, computing the visibility of segments from a point, performing
ray-shooting queries in constructive solid geometry (CSG) models, as
well as several geometric dominance problems.
These results are significant because large-scale problems involving geometric data are ubiquitous in spatial databases, geographic information systems (GIS), constraint logic programming, object oriented databases, statistics, virtual reality systems, and graphics. This work makes a big step, both theoretically and in practice, towards the effective management and manipulation of geometric data in external memory, which is an essential component of these applications.
We examine I/O-efficient data structures that provide
indexing support for new data models. The database languages of these
models include concepts from constraint programming (e.g., relational
tuples are generalized to conjunctions of constraints) and from
object-oriented programming (e.g., objects are organized in class
hierarchies). Let ![]() be the size of the database,
be the size of the database, ![]() the number of
classes,
the number of
classes, ![]() the page size on secondary storage, and
the page size on secondary storage, and ![]() the size of
the output of a query. (1) Indexing by one attribute in many
constraint data models is equivalent to external dynamic interval
management, which is a special case of external dynamic 2-dimensional
range searching. We present a semi-dynamic data structure for this
problem that has worst-case space
the size of
the output of a query. (1) Indexing by one attribute in many
constraint data models is equivalent to external dynamic interval
management, which is a special case of external dynamic 2-dimensional
range searching. We present a semi-dynamic data structure for this
problem that has worst-case space ![]() pages, query I/O time
pages, query I/O time
![]() and
and
![]() amortized
insert I/O time. Note that, for the static version of this problem,
this is the first worst-case optimal solution. (2) Indexing by one
attribute and by class name in an object-oriented model, where objects
are organized as a forest hierarchy of classes, is also a special case
of external dynamic 2-dimensional range searching. Based on this
observation, we first identify a simple algorithm with good worst-case
performance, query I/O time
amortized
insert I/O time. Note that, for the static version of this problem,
this is the first worst-case optimal solution. (2) Indexing by one
attribute and by class name in an object-oriented model, where objects
are organized as a forest hierarchy of classes, is also a special case
of external dynamic 2-dimensional range searching. Based on this
observation, we first identify a simple algorithm with good worst-case
performance, query I/O time
![]() , update I/O time
, update I/O time
![]() and space
and space
![]() pages for the class
indexing problem. Using the forest structure of the class hierarchy
and techniques from the constraint indexing problem, we improve its
query I/O time to
pages for the class
indexing problem. Using the forest structure of the class hierarchy
and techniques from the constraint indexing problem, we improve its
query I/O time to
![]() .
.
We define a new complexity measure, called object complexity, for hidden-surface elimination algorithms. This model is more appropriate than the standard scene complexity measure used in computational geometry for predicting the performance of these algorithms on current graphics rendering systems.
We also present an algorithm to determine the set of visible windows in
3-D scenes consisting of ![]() isothetic windows. It takes time
isothetic windows. It takes time ![]() , which is optimal. The algorithm solves in the object
complexity model the same problem that Bern addressed for the standard
scene complexity model.
, which is optimal. The algorithm solves in the object
complexity model the same problem that Bern addressed for the standard
scene complexity model.
We consider the practical problem of constructing binary space
partitions (BSPs) for a set ![]() of
of ![]() orthogonal, non-intersecting,
two-dimensional rectangles in three-dimensional Euclidean space such
that the aspect ratio
of each rectangle in
orthogonal, non-intersecting,
two-dimensional rectangles in three-dimensional Euclidean space such
that the aspect ratio
of each rectangle in ![]() is at most
is at most ![]() , for some constant
, for some constant
![]() . We present an
. We present an
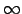 -time algorithm
to build a binary space partition of size
for
-time algorithm
to build a binary space partition of size
for ![]() . We also show that if
. We also show that if ![]() of the
of the ![]() rectangles in
rectangles in ![]() have
aspect ratios greater than
have
aspect ratios greater than ![]() , we can construct a BSP of
size
, we can construct a BSP of
size
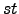 for
for ![]() in
time. The constants of proportionality in the
big-oh terms are linear in
in
time. The constants of proportionality in the
big-oh terms are linear in ![]() . We extend these results to
cases in which the input contains non-orthogonal or intersecting objects.
. We extend these results to
cases in which the input contains non-orthogonal or intersecting objects.
We present a new approach to designing data structures for the
important problem of external-memory range searching in two and three
dimensions. We construct data structures for answering range queries
in
![]() I/O operations, where
I/O operations, where
![]() is the number of points in the data structure,
is the number of points in the data structure, ![]() is the I/O
block size, and
is the I/O
block size, and ![]() is the number of points in the answer to the
query. We base our data structures on the novel concept of
is the number of points in the answer to the
query. We base our data structures on the novel concept of
![]() -approximate boundaries, which are manifolds that partition space
into regions based on the output size of queries at points within the
space.
-approximate boundaries, which are manifolds that partition space
into regions based on the output size of queries at points within the
space.
Our data structures answer a longstanding open problem by providing
three dimensional results comparable to those provided by Sairam and
Ramaswamy for the two dimensional case, though completely new
techniques are used. Ours is the first 3-D range search data
structure that simultaneously achieves both a base-![]() logarithmic
search overhead (namely,
logarithmic
search overhead (namely,
![]() ) and a fully
blocked output component (namely,
) and a fully
blocked output component (namely, ![]() ). This gives us an overall
I/O complexity extremely close to the well-known lower bound of
). This gives us an overall
I/O complexity extremely close to the well-known lower bound of
![]() . The space usage is more than linear by
a logarithmic or polylogarithmic factor, depending on type of range
search.
. The space usage is more than linear by
a logarithmic or polylogarithmic factor, depending on type of range
search.
We present a space- and I/O-optimal external-memory data structure for
answering stabbing queries on a set of dynamically maintained intervals.
Our data structure settles an open problem in databases and I/O algorithms
by providing the first optimal external-memory solution to the dynamic
interval management problem, which is a special case of 2-dimensional range
searching and a central problem for object-oriented and temporal databases
and for constraint logic programming. Our data structure simultaneously
uses optimal linear space (that is, ![]() blocks of disk space) and
achieves the optimal
blocks of disk space) and
achieves the optimal
![]() I/O query bound and
I/O query bound and ![]() I/O update bound, where
I/O update bound, where ![]() is the I/O block size and
is the I/O block size and ![]() the number of
elements in the answer to a query. Our structure is also the first optimal
external data structure for a 2-dimensional range searching problem that
has worst-case as opposed to amortized update bounds. Part of the data
structure uses a novel balancing technique for efficient worst-case
manipulation of balanced trees, which is of independent interest.
the number of
elements in the answer to a query. Our structure is also the first optimal
external data structure for a 2-dimensional range searching problem that
has worst-case as opposed to amortized update bounds. Part of the data
structure uses a novel balancing technique for efficient worst-case
manipulation of balanced trees, which is of independent interest.
Large-scale problems involving geometric data arise in numerous settings, and severe communication bottlenecks can arise in solving them. Work is needed in the development of I/O-efficient algorithms, as well as those that effectively utilize hierarchical memory. In order for new algorithms to be implemented efficiently in practice, the machines they run on must support fundamental external-memory operations. We discuss several advantages offered by TPIE (Transparent Parallel I/O Programming Environment) to enable I/O-efficient implementations.
General Terms: Algorithms, Design, Languages, Performance, Theory. Additional Key Words and Phrases: computational geometry, I/O, external memory, secondary memory, communication, disk drive, parallel disks.
We present the first systematic comparison of the performance of algorithms that construct Binary Space Partitions for orthogonal rectangles in three-dimensional Euclidean space. We compare known algorithms with our implementation of a variant of a recent algorithm of Agarwal et al. We show via an empirical study that their algorithm constructs BSPs of near-linear size in practice and performs better than most of the other algorithms in the literature.
We describe the first known algorithm for efficiently maintaining a
Binary Space Partition (BSP) for ![]() continuously moving segments in
the plane. Under reasonable assumptions on the motion, we show that
the total number of times the BSP changes is
continuously moving segments in
the plane. Under reasonable assumptions on the motion, we show that
the total number of times the BSP changes is ![]() , and that we can
update the BSP in
, and that we can
update the BSP in ![]() expected time per change. We also
consider the problem of constructing a BSP for
expected time per change. We also
consider the problem of constructing a BSP for ![]() triangles in
three-dimensional Euclidean space. We present a randomized algorithm
that constructs a BSP of expected size
triangles in
three-dimensional Euclidean space. We present a randomized algorithm
that constructs a BSP of expected size ![]() in
in
![]() expected time. We also describe a deterministic algorithm that
constructs a BSP of size
expected time. We also describe a deterministic algorithm that
constructs a BSP of size
![]() and height
and height ![]() in
in
![]() time, where
time, where ![]() is the number of
intersection points between the edges of the projections of the
triangles onto the
is the number of
intersection points between the edges of the projections of the
triangles onto the ![]() -plane.
-plane.
For a polyhedral terrain, the contour at ![]() -coordinate
-coordinate ![]() is
defined to be the intersection of the
plane
is
defined to be the intersection of the
plane ![]() with the terrain. In this paper, we study the
contour-line extraction problem, where we want to preprocess
the terrain into a data structure so that given a query
with the terrain. In this paper, we study the
contour-line extraction problem, where we want to preprocess
the terrain into a data structure so that given a query
![]() -coordinate
-coordinate ![]() , we can report the
, we can report the ![]() -contour quickly. This problem
is central to geographic information systems (GIS),
where terrains are often stored as Triangular Irregular Networks
(TINs). We present an I/O-optimal algorithm for this problem which
stores a terrain with
-contour quickly. This problem
is central to geographic information systems (GIS),
where terrains are often stored as Triangular Irregular Networks
(TINs). We present an I/O-optimal algorithm for this problem which
stores a terrain with ![]() vertices using
vertices using ![]() blocks,
where
blocks,
where ![]() is the size of a disk block, so that for any query
is the size of a disk block, so that for any query ![]() ,
the
,
the ![]() -contour can be computed using
-contour can be computed using
![]() I/O operations, where
I/O operations, where ![]() denotes the size of the
denotes the size of the ![]() -contour.
-contour.
We also present an improved algorithm for a more general problem of blocking bounded-degree planar graphs such as TINs (i.e., storing them on disk so that any graph traversal algorithm can traverse the graph in an I/O-efficient manner). We apply it to two problems that arise in GIS.
We describe a powerful framework for designing efficient batch algorithms for certain large-scale dynamic problems that must be solved using external memory. The class of problems we consider, which we call colorable external-decomposable problems, include rectangle intersection, orthogonal line segment intersection, range searching, and point location. We are particularly interested in these problems in two and higher dimensions. They have numerous applications in geographic information systems (GIS), spatial databases, and VLSI and CAD design. We present simplified algorithms for problems previously solved by more complicated approaches (such as rectangle intersection), and we present efficient algorithms for problems not previously solved in an efficient way (such as point location and higher-dimensional versions of range searching and rectangle intersection).
We give experimental results concerning the running time for our approach applied to the red-blue rectangle intersection problem, which is a key component of the extremely important database operation spatial join. Our algorithm scales well with the problem size, and for large problems sizes it greatly outperforms the well-known sweepline approach.
We show how to preprocess a set ![]() of points in
of points in ![]() -dimensional
Euclidean space to get an external memory data structure that
efficiently supports linear-constraint queries. Each query is in the
form of a linear constraint
-dimensional
Euclidean space to get an external memory data structure that
efficiently supports linear-constraint queries. Each query is in the
form of a linear constraint
![]() ; the data
structure must report all the points of
; the data
structure must report all the points of ![]() that satisfy the query.
(This problem is called halfspace range searching in the computational
geometry literature.) Our goal is to minimize the number of disk
blocks required to store the data structure and the number of disk
accesses (I/Os) required to answer a query. For
that satisfy the query.
(This problem is called halfspace range searching in the computational
geometry literature.) Our goal is to minimize the number of disk
blocks required to store the data structure and the number of disk
accesses (I/Os) required to answer a query. For ![]() , we present
the first near-linear size data structures that can answer
linear-constraint queries using an optimal number of I/Os. We also
present a linear-size data structure that can answer queries
efficiently in the worst case. We combine these two approaches to
obtain tradeoffs between space and query time. Finally, we show that
some of our techniques extend to higher dimensions.
, we present
the first near-linear size data structures that can answer
linear-constraint queries using an optimal number of I/Os. We also
present a linear-size data structure that can answer queries
efficiently in the worst case. We combine these two approaches to
obtain tradeoffs between space and query time. Finally, we show that
some of our techniques extend to higher dimensions.
In this paper, we examine the spatial join problem. In particular, we focus on the case when neither of the inputs is indexed. We present a new algorithm, Scalable Sweep-based Spatial Join (SSSJ), that is based on the distribution-sweeping technique recently proposed in computational geometry, and that is the first to achieve theoretically optimal bounds on internal computation time as well as I/O transfers. We present experimental results based on an efficient implementation of the SSSJ algorithm, and compare it to the state-of-the-art Partition-Based Spatial-Merge (PBSM) algorithm of Patel and DeWitt.
Our SSSJ algorithm performs an initial sorting step along the vertical
axis, after which we use the distribution-sweeping technique to partition
the input into a number of vertical strips, such that the data in each
strip can be efficiently processed by an internal-memory sweepline
algorithm. A key observation that allowed us to greatly improve the
practical performance of our algorithm is that in most sweepline algorithms
not all input data is needed in main memory at the same time. In our
initial experiments, we observed that on real-life two-dimensional spatial
data sets of size ![]() , the internal-memory sweepline algorithm requires
only
, the internal-memory sweepline algorithm requires
only ![]() memory space. This behavior (also known as the
square-root rule in the VLSI literature) implies that for real-life
two-dimensional data sets, we can bypass the vertical partitioning step and
directly perform the sweepline algorithm after the initial external sorting
step. We implemented SSSJ such that partitioning is only done when it is
detected that that the sweepline algorithm exhausts the internal
memory. This results in an algorithm that not only is extremely efficient
for real-life data but also offers guaranteed worst-case bounds and
predictable behavior on skewed and/or bad input data: Our experiments show
that SSSJ performs at least
memory space. This behavior (also known as the
square-root rule in the VLSI literature) implies that for real-life
two-dimensional data sets, we can bypass the vertical partitioning step and
directly perform the sweepline algorithm after the initial external sorting
step. We implemented SSSJ such that partitioning is only done when it is
detected that that the sweepline algorithm exhausts the internal
memory. This results in an algorithm that not only is extremely efficient
for real-life data but also offers guaranteed worst-case bounds and
predictable behavior on skewed and/or bad input data: Our experiments show
that SSSJ performs at least ![]() better than PBSM on real-life data sets,
and that it robustly handles skewed data on which PBSM suffers a serious
performance degeneration.
better than PBSM on real-life data sets,
and that it robustly handles skewed data on which PBSM suffers a serious
performance degeneration.
As part of our experimental work we experimented with a number of different
techniques for performing the internal sweepline. By using an efficient
partitioning heuristic, we were able to speed up the internal sweeping used
by PBSM by a factor of over ![]() on the average for real-life data sets. The
resulting improved PBSM then performs approximately
on the average for real-life data sets. The
resulting improved PBSM then performs approximately ![]() better than SSSJ
on the real-life data we used, and it is thus a good choice of algorithm
when the data is known not to be too skewed.
better than SSSJ
on the real-life data we used, and it is thus a good choice of algorithm
when the data is known not to be too skewed.
In this paper, we develop a simple technique for constructing a Binary Space Partition (BSP) for a set of orthogonal rectangles in three-dimensions. Our algorithm has the novel feature that it tunes its performance to the geometric properties of the rectangles, e.g., their aspect ratios.
We have implemented our algorithm and tested its performance on real data sets. We have also systematically compared the performance of our algorithm with that of other techniques presented in the literature. Our studies show that our algorithm constructs BSPs of near-linear size and small height in practice, has fast running times, and answers queries efficiently. It is a method of choice for constructing BSPs for orthogonal rectangles.
In recent years there has been an upsurge of interest in spatial databases. A major issue is how to efficiently manipulate massive amounts of spatial data stored on disk in multidimensional spatial indexes (data structures). Construction of spatial indexes (bulk loading) has been researched intensively in the database community. The continuous arrival of massive amounts of new data make it important to efficiently update existing indexes (bulk updating).
In this article we present a simple technique for performing bulk update and query operations on multidimensional indexes. We present our technique in terms of the so-called R-tree and its variants, as they have emerged as practically efficient indexing methods for spatial data. Our method uses ideas from the buffer tree lazy buffering technique and fully utilizes the available internal memory and the page size of the operating system. We give a theoretical analysis of our technique, showing that it is efficient both in terms of I/O communication, disk storage, and internal computation time. We also present the results of an extensive set of experiments showing that in practice our approach performs better than the previously best known bulk update methods with respect to update time, and that it produces a better quality index in terms of query performance. One important novel feature of our technique is that in most cases it allows us to perform a batch of updates and queries simultaneously. To be able to do so is essential in environments where queries have to be answered even while the index is being updated and reorganized.
We present an efficient external-memory dynamic data structure for point
location in monotone planar subdivisions. Our data structure uses
![]() disk blocks to store a monotone subdivision of size
disk blocks to store a monotone subdivision of size ![]() , where
, where
![]() is the size of a disk block. It supports queries in
is the size of a disk block. It supports queries in ![]() I/Os (worst-case) and updates in
I/Os (worst-case) and updates in ![]() I/Os (amortized).
I/Os (amortized).
We also propose a new variant of ![]() -trees, called level-balanced
-trees, called level-balanced
![]() -trees, which allow insert, delete, merge, and split operations in
-trees, which allow insert, delete, merge, and split operations in
![]() I/Os (amortized),
I/Os (amortized),
![]() , even if each node stores a pointer to its parent.
Here
, even if each node stores a pointer to its parent.
Here ![]() is the size of main memory. Besides being essential to our
point-location data structure, we believe that level-balanced
B-trees are of significant independent interest. They can, for
example, be used to dynamically maintain a planar st-graph using
is the size of main memory. Besides being essential to our
point-location data structure, we believe that level-balanced
B-trees are of significant independent interest. They can, for
example, be used to dynamically maintain a planar st-graph using
![]() I/Os
(amortized) per update, so that reachability queries can be answered in
I/Os
(amortized) per update, so that reachability queries can be answered in
![]() I/Os (worst case).
I/Os (worst case).
In this paper we consider the problem of constructing
planar orthogonal grid drawings (or more simply,
layouts) of graphs, with the goal of minimizing the number of
bends along the edges. We present optimal parallel algorithms
that construct graph layouts with ![]() maximum edge length,
maximum edge length, ![]() area, and at most
area, and at most ![]() bends (for biconnected graphs) and
bends (for biconnected graphs) and ![]() bends (for simply connected graphs).
All three of these quality measures for the layouts are optimal in the
worst case for biconnected graphs.
The algorithm runs on a CREW PRAM
in
bends (for simply connected graphs).
All three of these quality measures for the layouts are optimal in the
worst case for biconnected graphs.
The algorithm runs on a CREW PRAM
in ![]() time with
time with ![]() processors, thus achieving optimal
time and processor utilization.
Applications include VLSI layout, graph drawing, and wireless communication.
processors, thus achieving optimal
time and processor utilization.
Applications include VLSI layout, graph drawing, and wireless communication.
In this paper we settle several longstanding open problems in theory of indexability and external orthogonal range searching. In the first part of the paper, we apply the theory of indexability to the problem of two-dimensional range searching. We show that the special case of 3-sided querying can be solved with constant redundancy and access overhead. From this, we derive indexing schemes for general 4-sided range queries that exhibit an optimal tradeoff between redundancy and access overhead.
In the second part of the paper, we develop dynamic external memory data
structures for the two query types. Our structure for 3-sided queries
occupies ![]() disk blocks, and it supports insertions and deletions
in
disk blocks, and it supports insertions and deletions
in ![]() I/Os and queries in
I/Os and queries in
![]() I/Os, where
I/Os, where ![]() is the disk block size,
is the disk block size, ![]() is the number of points, and
is the number of points, and ![]() is the
query output size. These bounds are optimal. Our structure for general
(4-sided) range searching occupies
is the
query output size. These bounds are optimal. Our structure for general
(4-sided) range searching occupies
![]() disk blocks and answers queries in
disk blocks and answers queries in
![]() I/Os, which are optimal. It also supports updates in
I/Os, which are optimal. It also supports updates in
![]() I/Os.
I/Os.
This survey article is superseded by a more comprehensive book. The book is available online and is recommended as the preferable reference.
Slides for ICALP '99 talk (gzip-compressed postscript)
The data sets for many of today's computer applications are too large to fit within the computer's internal memory and must instead be stored on external storage devices such as disks. A major performance bottleneck can be the input/output communication (or I/O) between the external and internal memories. In this paper we discuss a variety of online data structures for external memory, some very old and some very new, such as hashing (for dictionaries), B-trees (for dictionaries and 1-D range search), buffer trees (for batched dynamic problems), interval trees with weight-balanced B-trees (for stabbing queries), priority search trees (for 3-sided 2-D range search), and R-trees and other spatial structures. We also discuss several open problems along the way.
Most spatial join algorithms either assume the existence of a spatial index structure that is traversed during the join process, or solve the problem by sorting, partitioning, or on-the-fly index construction. In this paper, we develop a simple plane-sweeping algorithm that unifies the index-based and non-index based approaches. This algorithm processes indexed as well as non-indexed inputs, extends naturally to multi-way joins, and can be built easily from a few standard operations. We present the results of a comparative study of the new algorithm with several index-based and non-index based spatial join algorithms. We consider a number of factors, including the relative performance of CPU and disk, the quality of the spatial indexes, and the sizes of the input relations. An important conclusion from our work is that using an index-based approach whenever indexes are available does not always lead to the best execution time, and hence we propose the use of a simple cost model to decide when to follow an index-based approach.
The potential and use of Geographic Information Systems (GIS) is rapidly increasing due to the increasing availability of massive amounts of geospatial data from projects like NASA's Mission to Planet Earth. However, the use of these massive datasets also exposes scalability problems with existing GIS algorithms. These scalability problems are mainly due to the fact that most GIS algorithms have been designed to minimize internal computation time, while I/O communication often is the bottleneck when processing massive amounts of data.
In this paper, we consider I/O-efficient algorithms for problems
on grid-based terrains. Detailed grid-based terrain data is
rapidly becoming available for much of the earth's surface. We
describe
![]() I/O algorithms for
several problems on
I/O algorithms for
several problems on ![]() by
by ![]() grids for which only
grids for which only
![]() algorithms were previously known. Here
algorithms were previously known. Here ![]() denotes the size
of the main memory and
denotes the size
of the main memory and ![]() the size of a disk block.
the size of a disk block.
We demonstrate the practical merits of our work by comparing the empirical performance of our new algorithm for the flow accumulation problem with that of the previously best known algorithm. Flow accumulation, which models flow of water through a terrain, is one of the most basic hydrologic attributes of a terrain. We present the results of an extensive set of experiments on real-life terrain datasets of different sizes and characteristics. Our experiments show that while our new algorithm scales nicely with dataset size, the previously known algorithm ``breaks down'' once the size of the dataset becomes bigger than the available main memory. For example, while our algorithm computes the flow accumulation for the Appalachian Mountains in about three hours, the previously known algorithm takes several weeks.
The problem of content-based image searching has received considerable attention in the last few years. Thousands of images are now available on the internet, and many important applications require searching of images in domains such as E-commerce, medical imaging, weather prediction, satellite imagery, and so on. Yet, content-based image querying is still largely unestablished as a mainstream field, nor is it widely used by search engines. We believe that two of the major hurdles for this poor acceptance are poor retrieval quality and usability.
In this paper, we introduce the CAMEL system--an acronym for Concept Annotated iMagE Libraries--as an effort to address both of the above problems. The CAMEL system provides and easy-to-use, and yet powerful, text-only query interface, which allows users to search for images based on visual concepts, identified by specifying relevant keywords. Conceptually, CAMEL annotates images with the visual concepts that are relevant to them. In practice, CAMEL defines visual concepts by looking at sample images off-line and extracting their relevant visual features. Once defined, such visual concepts can be used to search for relevant images on the fly, using content-based search methods. The visual concepts are stored in a Concept Library and are represented by an associated set of wavelet features, which in our implementation were extracted by the WALRUS image querying system. Even though the CAMEL framework applies independently of the underlying query engine, for our prototype we have chosen WALRUS as a back-end, due to its ability to extract and query with image region features.
CAMEL improves retrieval quality because it allows experts to build very accurate representations of visual concepts that can be used even by novice users. At the same time, CAMEL improves usability by supporting the familiar text-only interface currently used by most search engines on the web. Both improvements represent a departure from traditional approaches to improving image query systems--instead of focusing on query execution, we emphasize query specification by allowing simpler and yet more precise query specification.
Slides for a talk (Adobe pdf format)
This survey article is superseded by a more comprehensive book. The book is available online and is recommended as the preferable reference.
It is infeasible for a sensor database to contain the exact value of each sensor at all points in time. This uncertainty is inherent in these systems due to measurement and sampling errors, and resource limitations. In order to avoid drawing erroneous conclusions based upon stale data, the use of uncertainty intervals that model each data item as a range and associated probability density function (pdf) rather than a single value has recently been proposed. Querying these uncertain data introduces imprecision into answers, in the form of probability values that specify the likeliness the answer satisfies the query. These queries are more expensive to evaluate than their traditional counterparts but are guaranteed to be correct and more informative due to the probabilities accompanying the answers. Although the answer probabilities are useful, for many applications, it is only necessary to know whether the probability exceeds a given threshold; we term these Probabilistic Threshold Queries (PTQ). In this paper we address the efficient computation of these types of queries.
In particular, we develop two index structures and associated algorithms to efficiently answer PTQs. The first index scheme is based on the idea of augmenting uncertainty information to an R-tree. We establish the difficulty of this problem by mapping one-dimensional intervals to a two-dimensional space, and show that the problem of interval indexing with probabilities is significantly harder than interval indexing which is considered a well-studied problem. To overcome the limitations of this R-tree based structure, we apply a technique we call variance-based clustering, where data points with similar degrees of uncertainty are clustered together. Our extensive index structure can answer the queries for various kinds of uncertainty pdfs, in an almost optimal sense. We conduct experiments to validate the superior performance of both indexing schemes.
In an uncertain database, each data item is modeled as a range associated with a probability density function. Previous works for this kind of data have focused on simple queries such as range and nearest-neighbor queries. Queries that join multiple relations have not been addressed in earlier work despite the significance of joins in databases. In this paper, we address probabilistic join over uncertain data, essentially a query that augments the results with probability guarantees to indicate the likelihood of each join tuple being part of the result. We extend the notion of join operators, such as equality and inequality, for uncertain data. We also study the performance of probabilistic join. We observe that a user may only need to know whether the probability of the results exceeds a given threshold, instead of the precise probability value. By incorporating this constraint, it is possible to achieve much better performance. In particular, we develop three sets of optimization techniques, namely item-level, page-level and index-level pruning, for different join operators. These techniques facilitate pruning with little space and time overhead, and are easily adapted to most join algorithms. We verify the performance of these techniques experimentally.
We introduce a new variant of the popular Burrows-Wheeler transform (BWT) called Geometric Burrows-Wheeler Transform (GBWT). Unlike BWT, which merely permutes the text, GBWT converts the text into a set of points in 2-dimensional geometry. Using this transform, we can answer to many open questions in compressed text indexing: (1) Can compressed data structures be designed in external memory with similar performance as the uncompressed counterparts? (2) Can compressed data structures be designed for position restricted pattern matching? We also introduce a reverse transform, called Points2Text, which converts a set of points into text. This transform allows us to derive the best known lower bounds in compressed text indexing. We show strong equivalence between data structural problems in geometric range searching and text pattern matching. This provides a way to derive new results in compressed text indexing by translating the results from range searching.
Slides for a talk (Adobe pdf format)
Data sets in large applications are often too massive to fit completely inside the computer's internal memory. The resulting input/output communication (or I/O) between fast internal memory and slower external memory (such as disks) can be a major performance bottleneck. In this book we discuss the state of the art in the design and analysis of external memory (or EM) algorithms and data structures, where the goal is to exploit locality in order to reduce the I/O costs. We consider a variety of EM paradigms for solving batched and online problems efficiently in external memory.
For the batched problem of sorting and related problems like permuting and fast Fourier transform, the key paradigms include distribution and merging. The paradigm of disk striping offers an elegant way to use multiple disks in parallel. For sorting, however, disk striping can be nonoptimal with respect to I/O, so to gain further improvements we discuss prefetching, distribution, and merging techniques for using the disks independently. We also consider useful techniques for batched EM problems involving matrices (such as matrix multiplication and transposition), geometric data (such as finding intersections and constructing convex hulls) and graphs (such as list ranking, connected components, topological sorting, and shortest paths). In the online domain, canonical EM applications include dictionary lookup and range searching. The two important classes of indexed data structures are based upon extendible hashing and B-trees. The paradigms of filtering and bootstrapping provide a convenient means in online data structures to make effective use of the data accessed from disk. We also reexamine some of the above EM problems in slightly different settings, such as when the data items are moving, when the data items are variable-length (e.g., text strings), when the internal data representations are compressed, or when the allocated amount of internal memory can change dynamically.
Programming tools and environments are available for simplifying the EM programming task. During the course of the book, we report on some experiments in the domain of spatial databases using the TPIE system (Transparent Parallel I/O programming Environment). The newly developed EM algorithms and data structures that incorporate the paradigms we discuss are significantly faster than methods currently used in practice.
This book is an expanded version of an earlier survey article.
A new trend in the field of pattern matching is to design
indexing data structures
which take the space very close to that required by the
indexed text (in
entropy-compressed form) and also simultaneously achieve
good query performance. Two
popular indexes, namely the FM-index of Ferragina and Manzini and the
CSA of Grossi and Vitter,
achieve this goal by exploiting the Burrows-Wheeler
transform (BWT).
However, due to the intricate permutation structure of BWT,
no locality
of reference can be guaranteed when we perform pattern
matching with these indexes.
Chien et al. gave an alternative text
index which is based
on sparsifying the traditional suffix tree and maintaining
an auxiliary 2-D range query structure.
Given a text ![]() of length
of length ![]() drawn from a
drawn from a ![]() -sized
alphabet set,
they achieved an
-sized
alphabet set,
they achieved an
![]() -bit index for
-bit index for ![]() and
showed that this index can preserve locality in pattern
matching and hence
is amenable to be used in external-memory settings.
We improve upon this index and show how to apply entropy
compression to reduce index space.
Our index takes
and
showed that this index can preserve locality in pattern
matching and hence
is amenable to be used in external-memory settings.
We improve upon this index and show how to apply entropy
compression to reduce index space.
Our index takes
![]() bits of
space where
bits of
space where ![]() is the
is the ![]() th-order
empirical entropy of the text.
This is achieved by creating variable length blocks of text
using arithmetic coding.
th-order
empirical entropy of the text.
This is achieved by creating variable length blocks of text
using arithmetic coding.
Pattern matching on text data has been a fundamental field of Computer Science for nearly 40 years. Databases supporting full-text indexing functionality on text data are now widely used by biologists. In the theoretical literature, the most popular internal-memory index structures are the suffix trees and the suffix arrays, and the most popular external-memory index structure is the string B-tree. However, the practical applicability of these indexes has been limited mainly because of their space consumption and I/O issues. These structures use a lot more space (almost 20 to 50 times more) than the original text data and are often disk-resident.
Ferragina and Manzini (2005) and Grossi and Vitter (2005) gave the first compressed text indexes with efficient query times in the internal-memory model. Recently, Chien et al (2008) presented a compact text index in the external memory based on the concept of Geometric Burrows-Wheeler Transform. They also presented lower bounds which suggested that it may be hard to obtain a good index structure in the external memory.
In this paper, we investigate this issue from a practical point of view. On the positive side we show an external-memory text indexing structure (based on R-trees and KD-trees) that saves space by about an order of magnitude as compared to the standard String B-tree. While saving space, these structures also maintain a comparable I/O efficiency to that of String B-tree. We also show various space vs. I/O efficiency trade-offs for our structures.
Given a set
![]() of
of ![]() strings of
total length
strings of
total length ![]() , our task is to report the ``most
relevant'' strings for a given query pattern
, our task is to report the ``most
relevant'' strings for a given query pattern ![]() . This
involves somewhat more advanced query functionality than the
usual pattern matching, as some notion of ``most relevant''
is involved. In information retrieval literature, this task
is best achieved by using inverted indexes. However,
inverted indexes work only for some predefined set of
patterns. In the pattern matching community, the most
popular pattern-matching data structures are suffix trees
and suffix arrays. However, a typical suffix tree search
involves going through all the occurrences of the pattern
over the entire string collection, which might be a lot more
than the required relevant documents.
. This
involves somewhat more advanced query functionality than the
usual pattern matching, as some notion of ``most relevant''
is involved. In information retrieval literature, this task
is best achieved by using inverted indexes. However,
inverted indexes work only for some predefined set of
patterns. In the pattern matching community, the most
popular pattern-matching data structures are suffix trees
and suffix arrays. However, a typical suffix tree search
involves going through all the occurrences of the pattern
over the entire string collection, which might be a lot more
than the required relevant documents.
The first formal framework to study such kind of retrieval
problems was given by Muthukrishnan. He considered two
metrics for relevance: frequency and proximity. He took a
threshold-based approach on these metrics and gave data
structures taking ![]() words of space. We study
this problem in a slightly different framework of reporting
the top
words of space. We study
this problem in a slightly different framework of reporting
the top ![]() most relevant documents (in sorted order) under
similar and more general relevance metrics. Our framework
gives linear space data structure with optimal query times
for arbitrary score functions. As a corollary, it improves
the space utilization for the problems considered by
Muthukrishnan while maintaining optimal query performance.
We also develop compressed variants of these data structures
for several specific relevance metrics.
most relevant documents (in sorted order) under
similar and more general relevance metrics. Our framework
gives linear space data structure with optimal query times
for arbitrary score functions. As a corollary, it improves
the space utilization for the problems considered by
Muthukrishnan while maintaining optimal query performance.
We also develop compressed variants of these data structures
for several specific relevance metrics.
Slides for CPM '10 keynote talk (Adobe pdf)
The field of compressed data structures seeks to achieve fast search time, but using a compressed representation, ideally requiring less space than that occupied by the original input data. The challenge is to construct a compressed representation that provides the same functionality and speed as traditional data structures. In this invited presentation, we discuss some breakthroughs in compressed data structures over the course of the last decade that have significantly reduced the space requirements for fast text and document indexing. One interesting consequence is that, for the first time, we can construct data structures for text indexing that are competitive in time and space with the well-known technique of inverted indexes, but that provide more general search capabilities. Several challenges remain, and we focus in this presentation on two in particular: building I/O-efficient search structures when the input data are so massive that external memory must be used, and incorporating notions of relevance in the reporting of query answers.
Background: Genomic read alignment involves mapping (exactly or approximately) short reads from a particular individual onto a pre-sequenced reference genome of the same species. Because all individuals of the same species share the majority of their genomes, short reads alignment provides an alternative and much more efficient way to sequence the genome of a particular individual than does direct sequencing. Among many strategies proposed for this alignment process, indexing the reference genome and short read searching over the index is a dominant technique. Our goal is to design a space-efficient indexing structure with fast searching capability to catch the massive short reads produced by the next generation high-throughput DNA sequencing technology.
Results: We concentrate on indexing DNA sequences via sparse suffix arrays
(SSAs) and propose a new short read aligner named ![]() -RA (PSI-RA:
parallel sparse index read aligner). The motivation in using SSAs is
the ability to trade memory against time. It is possible to fine tune
the space consumption of the index based on the available memory of
the machine and the minimum length of the arriving pattern queries.
Although SSAs have been studied before for exact matching of short
reads, an elegant way of approximate matching capability was missing.
We provide this by defining the rightmost mismatch criteria that
prioritize the errors towards the end of the reads, where errors are
more probable.
-RA (PSI-RA:
parallel sparse index read aligner). The motivation in using SSAs is
the ability to trade memory against time. It is possible to fine tune
the space consumption of the index based on the available memory of
the machine and the minimum length of the arriving pattern queries.
Although SSAs have been studied before for exact matching of short
reads, an elegant way of approximate matching capability was missing.
We provide this by defining the rightmost mismatch criteria that
prioritize the errors towards the end of the reads, where errors are
more probable. ![]() -RA supports any number of mismatches in aligning
reads. We give comparisons with some of the well-known short read
aligners, and show that indexing a genome with SSA is a good
alternative to the Burrows-Wheeler transform or seed-based solutions.
-RA supports any number of mismatches in aligning
reads. We give comparisons with some of the well-known short read
aligners, and show that indexing a genome with SSA is a good
alternative to the Burrows-Wheeler transform or seed-based solutions.
Conclusions: ![]() -RA is expected to serve as a valuable tool in the alignment of
short reads generated by the next generation high-throughput
sequencing technology.
-RA is expected to serve as a valuable tool in the alignment of
short reads generated by the next generation high-throughput
sequencing technology. ![]() -RA is very fast in exact matching and
also supports rightmost approximate matching. The SSA structure that
-RA is very fast in exact matching and
also supports rightmost approximate matching. The SSA structure that
![]() -RA is built on naturally incorporates the modern multicore
architecture and thus further speed-up can be gained. All the
information, including the source code of
-RA is built on naturally incorporates the modern multicore
architecture and thus further speed-up can be gained. All the
information, including the source code of ![]() -RA, can be downloaded
at http://www.busillis.com/o_kulekci/PSIRA.zip.
-RA, can be downloaded
at http://www.busillis.com/o_kulekci/PSIRA.zip.
The wavelet tree data structure is a space-efficient technique
for rank and select queries that generalizes from binary characters to
an arbitrary multicharacter alphabet. It has become a key tool in
modern full-text indexing and data compression because of its
capabilities in compressing, indexing, and searching. We present a
comparative study of its practical performance regarding a wide range
of options on the dimensions of different coding schemes and tree
shapes. Our results are both theoretical and experimental:
(1) We show that the run-length ![]() coding size of wavelet trees
achieves the 0-order empirical entropy size of the original string
with leading constant 1, when the string's 0-order empirical entropy
is asymptotically less than the logarithm of the alphabet size. This
result complements the previous works that are dedicated to analyzing
run-length
coding size of wavelet trees
achieves the 0-order empirical entropy size of the original string
with leading constant 1, when the string's 0-order empirical entropy
is asymptotically less than the logarithm of the alphabet size. This
result complements the previous works that are dedicated to analyzing
run-length ![]() -encoded wavelet trees. It also reveals the
scenarios when run-length
-encoded wavelet trees. It also reveals the
scenarios when run-length ![]() encoding becomes practical.
(2) We introduce a full generic package of wavelet trees for a wide
range of options on the dimensions of coding schemes and tree shapes.
Our experimental study reveals the practical performance of the
various modifications.
encoding becomes practical.
(2) We introduce a full generic package of wavelet trees for a wide
range of options on the dimensions of coding schemes and tree shapes.
Our experimental study reveals the practical performance of the
various modifications.
T.-H. Ku, W.-K. Hon, R. Shah, S. V. Thankachan, and J. S. Vitter. ``Compressed Text Indexing With Wildcards,'' in preparation. An extended abstract appears in Proceedings of the 18th International Conference on String Processing and Information Retrieval (SPIRE '11), Pisa, Italy, October 2011, published in Lecture Notes in Computer Science, Springer, Berlin, Germany.
Let
![]() be a text of
total length
be a text of
total length ![]() , where characters of each
, where characters of each ![]() are chosen from an
alphabet
are chosen from an
alphabet ![]() of size
of size ![]() , and
, and ![]() denotes a wildcard
symbol. The text indexing with wildcards problem is to index
denotes a wildcard
symbol. The text indexing with wildcards problem is to index ![]() such
that when we are given a query pattern
such
that when we are given a query pattern ![]() , we can locate the
occurrences of
, we can locate the
occurrences of ![]() in
in ![]() efficiently. This problem has been applied
in indexing genomic sequences that contain single-nucleotide
polymorphisms (SNP) because SNP can be modeled as wildcards. Recently
Tam et al. (2009) and Thachuk (2011) have proposed succinct indexes
for this problem. In this paper, we present the first compressed
index for this problem, which takes only
efficiently. This problem has been applied
in indexing genomic sequences that contain single-nucleotide
polymorphisms (SNP) because SNP can be modeled as wildcards. Recently
Tam et al. (2009) and Thachuk (2011) have proposed succinct indexes
for this problem. In this paper, we present the first compressed
index for this problem, which takes only
![]() bits space, where
bits space, where ![]() is the
is the ![]() th-order
empirical entropy (
th-order
empirical entropy (
![]() ) of
) of ![]() .
.
Chien et al. [1, 2] introduced the geometric Burrows-Wheeler transform (GBWT) as the
first succinct text index for I/O-efficient pattern matching in external memory; it operates
by transforming a text ![]() into point set
into point set ![]() in the two-dimensional plane. In this paper
we introduce a practical succinct external memory text index, called mKD-GBWT. We
partition
in the two-dimensional plane. In this paper
we introduce a practical succinct external memory text index, called mKD-GBWT. We
partition ![]() into
into ![]() subregions by partitioning the x-axis into
subregions by partitioning the x-axis into ![]() intervals using the suffix
ranges of characters of
intervals using the suffix
ranges of characters of ![]() and partitioning the y-axis into
and partitioning the y-axis into ![]() intervals using characters of
intervals using characters of ![]() ,
where
,
where ![]() is the alphabet size of
is the alphabet size of ![]() . In this way, we can represent a point using fewer
bits and perform a query in a reduced region so as to improve the space usage and I/Os
of GBWT in practice. In addition, we plug a crit-bit tree into each node of string B-trees
to represent variable-length strings stored. Experimental results show that mKD-GBWT
provides significant improvement in space usage compared with the state-of-the-art indexing
techniques. The source code is available online [3].
. In this way, we can represent a point using fewer
bits and perform a query in a reduced region so as to improve the space usage and I/Os
of GBWT in practice. In addition, we plug a crit-bit tree into each node of string B-trees
to represent variable-length strings stored. Experimental results show that mKD-GBWT
provides significant improvement in space usage compared with the state-of-the-art indexing
techniques. The source code is available online [3].